Structured Logging: Best Practices & JSON Examples
In structured logging, log messages are broken down into key-value pairs, making it easier to search, filter, and analyze logs. This is in contrast to traditional logging, which usually consists of unstructured text that is difficult to parse and analyze.
What is structured logging?
Structured logging is the practice of capturing and storing log messages in a structured and organized format.
Traditional logging often involves printing raw text messages to log files, which can be difficult to parse and analyze programmatically.
In contrast, structured logging formats log messages as key-value pairs or in structured data formats such as JSON or XML.
Common logging challenges
Organizations face several challenges with traditional logging approaches:
- Difficulty in parsing and analyzing unstructured log data
- Inconsistent log formats across different services
- High storage costs due to inefficient log formats
- Complex log aggregation and correlation
- Limited searchability and filtering capabilities
Use cases for structured logging
Structured logging proves valuable across various application types, each with its specific requirements and challenges:
Microservices Architecture
When a request flows through multiple services, structured logs help track its journey and identify issues. For comprehensive microservices observability strategies, see our debugging microservices guide.
{
"service": "payment-processor",
"trace_id": "abc-123-def-456",
"event": "payment_initiated",
"upstream_service": "order-service",
"downstream_service": "payment-gateway",
"request_id": "req_789",
"latency_ms": 145
}
Service interaction tracking helps reveal communication patterns and bottlenecks. Request flow monitoring shows how operations move through your system, while distributed tracing lets you correlate errors across services and debug issues faster.
High-Load Applications
Applications handling thousands of requests per second require sophisticated logging strategies. Structured logging helps monitor and optimize performance:
{
"component": "api-gateway",
"event": "request_processed",
"endpoint": "/api/v1/users",
"method": "GET",
"response_time_ms": 45,
"cpu_usage_percent": 78,
"memory_usage_mb": 1240,
"concurrent_requests": 156
}
Performance monitoring becomes more efficient when logs include specific metrics and timings. Resource usage tracking helps identify potential memory leaks or CPU bottlenecks, while systematic logging of performance metrics helps identify and resolve bottlenecks before they affect users.
Security-Critical Systems
When working with sensitive data and compliance requirements, well-implemented logging becomes your primary tool for security oversight:
{
"system": "authentication-service",
"event": "login_attempt",
"status": "failed",
"reason": "invalid_2fa",
"ip_address": "192.168.1.1",
"geo_location": "US-NY",
"user_agent": "Mozilla/5.0...",
"attempt_count": 3,
"security_level": "high"
}
Why to use structured logging?
Structured logging provides the following benefits:
- Improved readability. The structured format makes log messages more human-readable, allowing developers and operators to easily understand the content without relying solely on raw text parsing.
- Better searching and filtering. Structured data makes it easier to search for specific log entries or filter logs based on specific criteria. This is especially useful for large-scale applications with large amounts of log data.
- Easy integration with tools. Structured logs can be ingested and processed by various log management and analysis tools, enabling powerful analysis, visualization, and monitoring of application behavior.
- Improved debugging and troubleshooting. When log messages are structured, it is easier to include relevant contextual information, such as timestamps, error codes, and specific attributes related to the logged events, which facilitates effective debugging and troubleshooting.
- Consistency and scalability. Structured logging promotes a consistent and uniform log format throughout the application, making it easier to scale logging capabilities and maintain logs in a standardized manner.
Structured logging forms a critical foundation for effective data observability practices. By providing consistent, machine-parsable log data, structured logging enables more sophisticated monitoring and analysis of data systems. Learn more in our data observability guide which explores how these practices work together.
Quick Setup Guide
Getting started with structured logging in your application takes just a few minutes. Here's how to set up structured logging for the most popular languages and frameworks.
Python with structlog
Install structlog and configure basic structured logging:
pip install structlog
import structlog
# Configure structlog
structlog.configure(
processors=[
structlog.processors.TimeStamper(fmt="iso"),
structlog.processors.add_log_level,
structlog.processors.JSONRenderer()
]
)
# Create logger
logger = structlog.get_logger()
# Use structured logging
logger.info(
"user_login",
user_id="12345",
ip_address="192.168.1.1",
success=True
)
Output:
{"event": "user_login", "user_id": "12345", "ip_address": "192.168.1.1", "success": true, "timestamp": "2025-01-08T14:30:00Z", "level": "info"}
What this does: Structlog automatically adds timestamps and formats logs as JSON. The JSONRenderer() processor converts all log calls to valid JSON format. For production Python logging patterns, see our Python logging guide.
Java with Logback and Logstash Encoder
Add dependency to your pom.xml:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.4</version>
</dependency>
Configure logback.xml:
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
Use in code:
import net.logstash.logback.argument.StructuredArguments;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
Logger logger = LoggerFactory.getLogger(MyClass.class);
logger.info("User login",
StructuredArguments.kv("user_id", "12345"),
StructuredArguments.kv("ip_address", "192.168.1.1"),
StructuredArguments.kv("success", true)
);
What this does: Logstash encoder automatically converts SLF4J log calls to JSON format. The StructuredArguments.kv() method adds key-value pairs that appear as separate fields in JSON output. This works with existing logging infrastructure without code changes.
Node.js with Pino
Install pino:
npm install pino
const pino = require('pino')();
pino.info({
event: 'user_login',
user_id: '12345',
ip_address: '192.168.1.1',
success: true
});
Output:
{"level":30,"time":1673184600000,"event":"user_login","user_id":"12345","ip_address":"192.168.1.1","success":true}
What this does: Pino is one of the fastest JSON loggers for Node.js. It automatically adds timestamps and converts objects to JSON with minimal performance overhead (~10x faster than Winston). The flat structure makes logs easy to parse and query.
Go with slog (Standard Library)
Go 1.21+ includes structured logging in the standard library:
package main
import (
"log/slog"
"os"
)
func main() {
// Create JSON handler
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
// Use structured logging
logger.Info("User login",
"user_id", "12345",
"ip_address", "192.168.1.1",
"success", true,
)
}
What this does: Go's built-in slog package (since Go 1.21) provides structured logging without external dependencies. The JSONHandler automatically formats all logs as JSON. For advanced Go logging patterns, see our Golang logging comparison and OpenTelemetry Slog integration guide.
Ruby with Semantic Logger
Install semantic_logger:
gem install semantic_logger
require 'semantic_logger'
# Configure JSON output
SemanticLogger.add_appender(io: STDOUT, formatter: :json)
logger = SemanticLogger['MyApp']
logger.info(
'User login',
user_id: '12345',
ip_address: '192.168.1.1',
success: true
)
What this does: Semantic Logger provides structured logging for Ruby with JSON output support. The formatter: :json parameter ensures all logs are formatted as valid JSON objects with timestamps and severity levels included automatically.
.NET with Serilog
Install Serilog:
dotnet add package Serilog
dotnet add package Serilog.Sinks.Console
dotnet add package Serilog.Formatting.Compact
Configure in your application:
using Serilog;
Log.Logger = new LoggerConfiguration()
.WriteTo.Console(new CompactJsonFormatter())
.CreateLogger();
Log.Information("User login {@LoginEvent}", new {
UserId = "12345",
IpAddress = "192.168.1.1",
Success = true
});
What this does: Serilog with CompactJsonFormatter outputs logs in a compact JSON format optimized for log aggregators like Elasticsearch. The @ destructuring operator serializes complex objects as nested JSON structures. Serilog's sinks system allows routing logs to multiple destinations simultaneously.
Verifying Your Setup
After implementing structured logging, verify it's working correctly:
- Check log output format: Logs should be valid JSON
- Verify all fields: Ensure timestamp, level, and custom fields appear
- Test with log aggregation tools: Import logs into tools like Elasticsearch or Uptrace
# Test that logs are valid JSON
tail -f application.log | jq .
# Should output formatted JSON
{
"timestamp": "2025-01-08T14:30:00Z",
"level": "info",
"event": "user_login",
"user_id": "12345"
}
Structured log formats
Structured logging can be implemented using various data formats, with JSON being one of the most commonly used due to its simplicity and human-readability.
However, other formats can also be used depending on the requirements of the application and the logging framework in use.
JSON format
JSON is a lightweight data exchange format that is easy for both humans and machines to read and write. It represents data as key-value pairs and arrays, making it an excellent choice for structured logging due to its simplicity and widespread support.
Example for a web application:
{
"timestamp": "2025-01-08T12:34:56Z",
"level": "ERROR",
"service": "payment-service",
"message": "Payment processing failed",
"error": {
"code": "INSUFFICIENT_FUNDS",
"message": "Account balance too low"
},
"context": {
"user_id": "12345",
"transaction_id": "tx_789",
"amount": 150.75,
"currency": "USD"
},
"request": {
"method": "POST",
"path": "/api/v1/payments",
"ip": "192.168.1.1"
}
}
You can also use JSON to include structured data in your log messages:
request failed {"http.method": "GET", "http.route": "/users/:id", "enduser.id": 123, "foo": "hello world"}
logfmt
This format represents log entries as a series of key-value pairs separated by delimiters such as spaces or tabs. It is simple and easy to implement.
If a value contains a space, you must enclose it in quotation marks. For example:
request failed http.method=GET http.route=/users/:id enduser.id=123 foo="hello world"
Format Comparison
| Format | Pros | Cons | Size Overhead | Parse Speed |
|---|---|---|---|---|
| JSON | Human-readable, Widely supported | Verbose | High | Medium |
| logfmt | Compact, Easy to read | Limited nested structure | Low | High |
| Raw text | Minimal size | Hard to parse | Minimal | Slow |
Free format
If your library does not support structured logging, you can still improve grouping by quoting params:
# good
can't parse string: "the original string"
"foo" param can't be empty
# bad
can't parse string: the original string
foo param can't be empty
Language-Specific Guides
For comprehensive language-specific logging guides with advanced patterns and production best practices:
- Python: See our complete Python logging guide for advanced configuration, handlers, formatters, and production patterns
- Golang: Check Golang logging libraries comparison and OpenTelemetry Slog integration for Go 1.21+ structured logging
- Kubernetes: For container logging, see kubectl logs command reference and best practices
- Docker: Learn Docker logging with tail, follow, and filtering options
Best Practices and Common Pitfalls
Implementing structured logging effectively requires careful consideration of various practices and potential issues. Following established best practices helps ensure your logging system remains maintainable, efficient, and valuable for troubleshooting and monitoring.
Best Practices
Consistent Field Names
When implementing structured logging across multiple services, maintaining consistent field names is crucial. This ensures easier log aggregation and analysis. For example, always use the same field name for user identification:
// Good - consistent naming
{"user_id": "12345", "action": "login"}
{"user_id": "12345", "action": "purchase"}
// Bad - inconsistent naming
{"userId": "12345", "action": "login"}
{"user": "12345", "action": "purchase"}
Correlation IDs
Correlation IDs are essential for tracking requests across distributed systems. Each request should receive a unique ID that's passed through all services, enabling you to trace the entire request flow from entry point to completion.
Why Correlation IDs Matter:
In microservices architectures, a single user request often triggers operations across multiple services. Without correlation IDs, tracking the request flow becomes nearly impossible. For example, an e-commerce checkout might involve: API Gateway → Auth Service → Order Service → Payment Service → Inventory Service. A correlation ID links all these operations together.
Correlation ID Format Standards:
Choose a format that balances uniqueness with readability:
// UUID v4 (recommended for production)
{
"correlation_id": "550e8400-e29b-41d4-a716-446655440000",
"trace_id": "550e8400-e29b-41d4-a716-446655440000",
"span_id": "7a085853-4b1e-4b8f-9c3e-5d2f1a8b9c7d"
}
// Custom format with prefix (easier to identify in logs)
{
"correlation_id": "req_2025_01_08_abc123",
"request_id": "req_abc123"
}
// Timestamp-based (sortable, includes time context)
{
"correlation_id": "20250108-143045-abc123-xyz789"
}
Propagating Correlation IDs:
Correlation IDs must be propagated through all service calls. Here's how to implement this across different technologies:
Python (Flask/FastAPI):
import uuid
from contextvars import ContextVar
from fastapi import FastAPI, Request
import structlog
# Store correlation ID in context
correlation_id_var: ContextVar[str] = ContextVar('correlation_id')
# Create logger
logger = structlog.get_logger()
app = FastAPI()
@app.middleware("http")
async def add_correlation_id(request: Request, call_next):
# Extract from header or generate new
correlation_id = request.headers.get(
'X-Correlation-ID',
str(uuid.uuid4())
)
correlation_id_var.set(correlation_id)
# Log with correlation ID
logger.info(
"Request received",
correlation_id=correlation_id,
method=request.method,
path=request.url.path
)
response = await call_next(request)
response.headers['X-Correlation-ID'] = correlation_id
return response
# Use in downstream calls
import httpx
async def call_downstream_service():
correlation_id = correlation_id_var.get()
async with httpx.AsyncClient() as client:
response = await client.get(
"https://downstream-service/api",
headers={"X-Correlation-ID": correlation_id}
)
return response
Java (Spring Boot):
import org.springframework.web.filter.OncePerRequestFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.slf4j.MDC;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.UUID;
public class CorrelationIdFilter extends OncePerRequestFilter {
private static final String CORRELATION_ID_HEADER = "X-Correlation-ID";
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain
) throws ServletException, IOException {
String correlationId = request.getHeader(CORRELATION_ID_HEADER);
if (correlationId == null) {
correlationId = UUID.randomUUID().toString();
}
MDC.put("correlation_id", correlationId);
response.setHeader(CORRELATION_ID_HEADER, correlationId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.clear();
}
}
}
// Configure in application
@Configuration
public class WebConfig {
@Bean
public FilterRegistrationBean<CorrelationIdFilter> correlationIdFilter() {
FilterRegistrationBean<CorrelationIdFilter> registrationBean =
new FilterRegistrationBean<>();
registrationBean.setFilter(new CorrelationIdFilter());
registrationBean.addUrlPatterns("/*");
return registrationBean;
}
}
// Use in logs
import net.logstash.logback.argument.StructuredArguments;
logger.info("Processing payment",
StructuredArguments.kv("correlation_id", MDC.get("correlation_id")),
StructuredArguments.kv("amount", amount),
StructuredArguments.kv("user_id", userId)
);
Node.js (Express):
const express = require('express');
const { v4: uuidv4 } = require('uuid');
const pino = require('pino');
const logger = pino();
const app = express();
// Correlation ID middleware
app.use((req, res, next) => {
const correlationId = req.headers['x-correlation-id'] || uuidv4();
// Store in request object
req.correlationId = correlationId;
// Add to response headers
res.setHeader('X-Correlation-ID', correlationId);
// Log incoming request
logger.info({
correlation_id: correlationId,
method: req.method,
path: req.path,
event: 'request_received'
});
next();
});
// Use in route handlers
app.get('/api/orders', async (req, res) => {
const { correlationId } = req;
logger.info({
correlation_id: correlationId,
event: 'fetching_orders'
});
// Pass to downstream services
const response = await fetch('https://downstream/api', {
headers: {
'X-Correlation-ID': correlationId
}
});
res.json(await response.json());
});
Go:
package main
import (
"context"
"github.com/google/uuid"
"log/slog"
"net/http"
)
type contextKey string
const correlationIDKey contextKey = "correlation_id"
func correlationIDMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
correlationID := r.Header.Get("X-Correlation-ID")
if correlationID == "" {
correlationID = uuid.New().String()
}
// Add to context
ctx := context.WithValue(r.Context(), correlationIDKey, correlationID)
// Add to response header
w.Header().Set("X-Correlation-ID", correlationID)
// Log with correlation ID
slog.InfoContext(ctx, "Request received",
"correlation_id", correlationID,
"method", r.Method,
"path", r.URL.Path,
)
next.ServeHTTP(w, r.WithContext(ctx))
})
}
// Extract correlation ID from context
func getCorrelationID(ctx context.Context) string {
if id, ok := ctx.Value(correlationIDKey).(string); ok {
return id
}
return ""
}
// Use in handlers
func handleOrder(w http.ResponseWriter, r *http.Request) {
correlationID := getCorrelationID(r.Context())
slog.Info("Processing order",
"correlation_id", correlationID,
"user_id", "12345",
)
}
Best Practices for Correlation IDs in JSON Logs:
{
"timestamp": "2025-01-08T14:30:00Z",
"level": "INFO",
"service": "payment-service",
"correlation_id": "550e8400-e29b-41d4-a716-446655440000",
"trace_id": "550e8400-e29b-41d4-a716-446655440000",
"span_id": "7a085853-4b1e-4b8f-9c3e-5d2f1a8b9c7d",
"parent_span_id": "6c9f4d2e-3a1b-4e5c-9d8f-2a7b3c6e9f1d",
"user_id": "user_12345",
"event": "payment_processed",
"amount": 99.99,
"currency": "USD"
}
Common Patterns:
- Entry Point Generation: Generate correlation ID at API gateway or load balancer
- Header Propagation: Use
X-Correlation-IDorX-Request-IDheader (standardize across organization) - Context Storage: Store in thread-local storage (MDC in Java, context vars in Python)
- Downstream Propagation: Always forward correlation ID to downstream services
- Response Headers: Include correlation ID in response for client-side correlation
- Database Operations: Include correlation ID in database queries for query tracing
Troubleshooting with Correlation IDs:
When debugging issues, search logs by correlation ID to see the complete request flow:
# Search logs for specific request
grep "550e8400-e29b-41d4-a716-446655440000" application.log
# In log aggregation tools (e.g., Elasticsearch)
correlation_id:"550e8400-e29b-41d4-a716-446655440000"
This reveals the complete timeline:
{"time": "14:30:00.100", "service": "api-gateway", "event": "request_received"}
{"time": "14:30:00.150", "service": "auth-service", "event": "user_authenticated"}
{"time": "14:30:00.200", "service": "order-service", "event": "order_created"}
{"time": "14:30:00.350", "service": "payment-service", "event": "payment_processed"}
{"time": "14:30:00.400", "service": "inventory-service", "event": "inventory_updated"}
{"time": "14:30:00.450", "service": "api-gateway", "event": "response_sent"}
Context Information
Every log entry should contain sufficient context to understand the event without requiring additional lookups. Include relevant business context, technical details, and environmental information:
{
"event": "payment_failed",
"amount": 99.99,
"currency": "USD",
"payment_provider": "stripe",
"error_code": "insufficient_funds",
"customer_type": "premium",
"environment": "production"
}
Common Pitfalls
Sensitive Data Exposure
One of the most critical mistakes is logging sensitive information. Consider this example:
// Bad - exposing sensitive data
{
"user_email": "john@example.com",
"credit_card": "4111-1111-1111-1111",
"password": "secretpass"
}
// Good - masked sensitive data
{
"user_email_hash": "a1b2c3...",
"credit_card_last4": "1111",
"password": "[REDACTED]"
}
Timestamp Consistency
Inconsistent timestamp formats can make log analysis difficult. Always use UTC and ISO 8601 format:
// Good
{"timestamp": "2025-01-08T14:30:00Z"}
// Bad
{"timestamp": "01/08/24 14:30:00"}
{"time": "2025-01-08 14:30:00 +0200"}
Performance Considerations
Log Sampling Strategies
Choosing the right sampling strategy is crucial for high-volume applications. Here's how different strategies work:
Probabilistic Sampling
This approach randomly samples a percentage of log entries:
import random
def should_log(sampling_rate=0.1):
return random.random() < sampling_rate
if should_log():
logger.info("User action", extra={"user_id": "123"})
Rate Limiting
Implement rate limiting to cap the number of logs per time window:
from datetime import datetime, timedelta
class RateLimitedLogger:
def __init__(self, max_logs_per_second=100):
self.max_logs = max_logs_per_second
self.counter = 0
self.window_start = datetime.now()
def should_log(self):
now = datetime.now()
if now - self.window_start > timedelta(seconds=1):
self.counter = 0
self.window_start = now
if self.counter < self.max_logs:
self.counter += 1
return True
return False
High-Load Handling
Asynchronous Logging
Implement asynchronous logging to prevent blocking operations:
import asyncio
import aiofiles
async def async_log(message, file_path):
async with aiofiles.open(file_path, mode='a') as file:
await file.write(message + '\n')
Batch Processing
Group logs into batches to reduce I/O operations:
class BatchLogger:
def __init__(self, batch_size=100):
self.batch = []
self.batch_size = batch_size
def add_log(self, log_entry):
self.batch.append(log_entry)
if len(self.batch) >= self.batch_size:
self.flush()
def flush(self):
if self.batch:
self._write_batch(self.batch)
self.batch = []
Security Guidelines
Logging systems play a dual role in application security: they're essential for security monitoring and audit trails, but they can also become a security vulnerability if not properly secured.
Modern applications process vast amounts of sensitive data, from personal information to business-critical details, making it crucial to implement proper security measures for your logging infrastructure.
This section covers key data protection practices and maintaining secure logging operations.
Sensitive Data Protection
PII Masking
Implement robust PII masking using regular expressions and lookup tables:
import re
PII_PATTERNS = {
'email': r'\b[\w\.-]+@[\w\.-]+\.\w+\b',
'credit_card': r'\b\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4}\b'
}
def mask_pii(log_entry):
for pii_type, pattern in PII_PATTERNS.items():
log_entry = re.sub(pattern, f'[MASKED_{pii_type}]', log_entry)
return log_entry
Encryption
For sensitive logs that must be retained, implement encryption:
from cryptography.fernet import Fernet
class EncryptedLogger:
def __init__(self, encryption_key):
self.cipher_suite = Fernet(encryption_key)
def log_sensitive(self, message):
encrypted_message = self.cipher_suite.encrypt(message.encode())
self._write_encrypted_log(encrypted_message)
Log Retention and Audit
Implement a comprehensive log retention policy that balances security requirements with storage constraints:
class LogRetentionManager:
def __init__(self, retention_days=30):
self.retention_days = retention_days
def cleanup_old_logs(self):
cutoff_date = datetime.now() - timedelta(days=self.retention_days)
# Implementation of log cleanup logic
Troubleshooting
Handling High Log Volume
When facing high log volume issues, implement a systematic approach:
- Analyze current logging patterns:
def analyze_log_patterns(logs):
pattern_counts = {}
for log in logs:
pattern = extract_log_pattern(log)
pattern_counts[pattern] = pattern_counts.get(pattern, 0) + 1
return pattern_counts
- Implement dynamic sampling based on patterns:
def should_log_pattern(pattern, pattern_counts):
if pattern_counts[pattern] > THRESHOLD:
return random.random() < 0.1
return True
Logging backend
Uptrace is an open source APM for OpenTelemetry that supports logs, traces, and metrics. You can use it to monitor applications and troubleshoot issues.
Uptrace natively supports structured logging and automatically parses log messages to extract the structured data and store it as attributes.
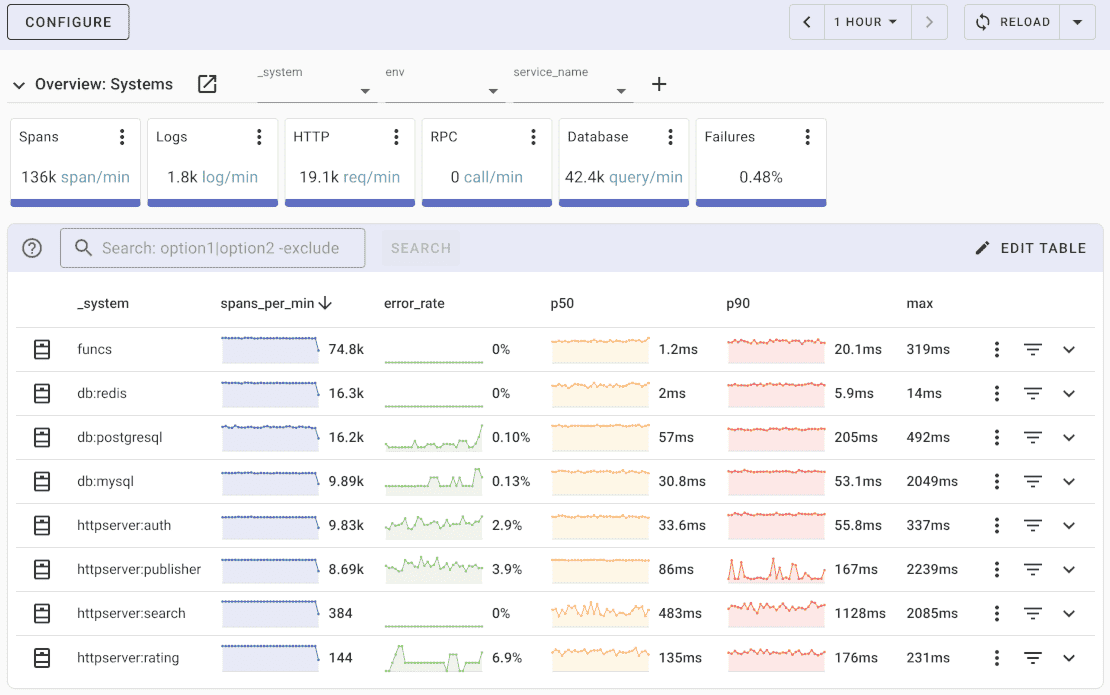
Uptrace comes with an intuitive query builder, rich dashboards, alerting rules, notifications, and integrations for most languages and frameworks.
Uptrace can process billions of logs on a single server and allows you to monitor your applications at 10x lower cost.
In just a few minutes, you can try Uptrace by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.
Conclusion
Structured logging enables better log management, improved troubleshooting, and better application monitoring, resulting in more efficient and reliable software development and maintenance processes.
FAQ
How much logging is appropriate for production applications? The optimal logging volume depends on your application's complexity and requirements. High-traffic applications typically implement sampling strategies, logging 1-10% of routine operations while maintaining 100% coverage for errors and critical events. Consider storage costs and performance impact: logging can consume 1-5% of your application's resources in a well-configured system.
What's the performance impact of structured logging? Modern structured logging libraries add minimal overhead, typically 0.1-0.5ms per log entry. However, synchronous disk I/O can impact performance significantly. Implementing asynchronous logging with buffering can reduce this to microseconds. For high-throughput systems processing 10,000+ requests per second, consider implementing batching and sampling strategies.
How should I handle log rotation in containerized environments? Container logs are typically handled differently from traditional applications. Instead of file-based rotation, implement log streaming to external aggregators. If using file-based logging, configure retention based on size (e.g., 100MB per container) and time (7-30 days). Many organizations retain the last 2-3 rotated files for immediate troubleshooting.
What's the best approach for handling sensitive data in logs? Implement multi-layer protection for sensitive data. First, use pattern matching to identify and mask PII (emails, credit cards, SSNs) before logging. Second, encrypt logs at rest using industry-standard algorithms (AES-256). Third, implement role-based access control for log viewing. Some organizations maintain separate logging streams for sensitive and non-sensitive data.
How can I effectively debug issues across microservices? Correlation IDs are essential for distributed tracing. Generate a unique ID for each request chain and propagate it across services. Tools like OpenTelemetry can automate this process with automatic trace context propagation. Also, implement consistent timestamp formats (ISO 8601 in UTC) and log levels across services. Many organizations find that 60-70% of debugging time is saved with proper correlation implementation.
What are the storage requirements for structured logging? Storage needs vary by format choice and retention policies. JSON logging typically requires 1.5-2x more storage than plain text, while binary formats can reduce size by 30-50%. For a medium-sized application (1M requests/day), expect 1-5GB of logs per day before compression. Implementing GZIP compression typically reduces storage needs by 60-80%.
How should I handle logging during system outages? Implement a local buffer for logs when external logging systems are unavailable. Configure your logging library to maintain the last 1000-10000 entries in memory, with periodic writes to local storage. Once connectivity is restored, implement smart retry logic with exponential backoff. Critical error logs should have redundant storage paths to ensure preservation during outages.
What is structured logging and how does it differ from traditional logging? Structured logging formats log messages as key-value pairs (e.g., JSON: {"user_id": "123", "action": "login"}) instead of plain text strings (e.g., "User 123 logged in"). This makes logs machine-readable, searchable by specific fields, and easier to analyze with log management tools. Traditional logs require regex parsing, while structured logs can be queried directly like database records.
What are the main benefits of structured logging? The primary benefits include: (1) Easy filtering and searching by specific fields without regex, (2) Automatic parsing by log aggregation tools like Elasticsearch or Splunk, (3) Consistent format across services enabling easier debugging, (4) Ability to add contextual data (user IDs, request IDs) without changing log message format, (5) Better performance in log analysis tools due to indexed fields.
Which structured logging format should I choose: JSON or logfmt? Choose JSON for maximum compatibility with log management tools, complex nested data structures, and human readability. JSON is ideal for microservices and cloud-native applications. Choose logfmt for lower storage overhead (30-40% smaller), faster parsing, and simpler single-level key-value pairs. Many high-performance systems use logfmt for reduced I/O. For most applications, JSON is recommended due to broader ecosystem support.
What are the best practices for JSON logging? Always include: (1) ISO 8601 timestamp in UTC ("timestamp": "2025-01-08T14:30:00Z"), (2) Log level as a field ("level": "ERROR"), (3) Consistent field names across services (use user_id, not mixing userId and user), (4) Correlation IDs for distributed tracing, (5) Structured error information instead of stack traces as strings. Avoid logging sensitive data like passwords or credit cards. Use nested objects for related data but keep structure shallow (2-3 levels max) for better query performance.
How do I implement structured logging in microservices? Establish organization-wide standards: (1) Use the same logging library and format across all services, (2) Generate correlation IDs at API gateway and propagate via headers (X-Correlation-ID), (3) Include service name, version, and environment in every log entry, (4) Implement centralized log aggregation (e.g., ELK stack, Loki), (5) Use consistent field naming conventions documented in a shared schema. Each service should log: incoming requests, outgoing requests to other services, database queries, and errors with full context. For comprehensive microservices monitoring patterns, see our microservices architecture guide.
What should I include in every log entry? Essential fields for every log entry: (1) timestamp - ISO 8601 in UTC, (2) level - ERROR, WARN, INFO, DEBUG, (3) service or application name, (4) correlation_id or request_id for tracing, (5) message or event describing what happened. Additional recommended fields: environment (production/staging), version, host or instance_id. For errors, include: error_code, error_message, stack_trace. For requests: http_method, http_path, http_status, duration_ms, user_id.
How do I set up structured logging for my application? Follow these steps: (1) Install a structured logging library for your language (Python: structlog, Java: Logback with Logstash encoder, Node.js: pino, Go: slog), (2) Configure JSON output format, (3) Add timestamp and log level processors, (4) Set up correlation ID propagation in middleware/filters, (5) Configure output destination (stdout for containers, file for VMs), (6) Test with tail -f app.log | jq . to verify JSON format. See the Quick Setup Guide section for language-specific examples.
Can I use structured logging with existing logging libraries? Yes, most popular logging libraries support structured logging through extensions or encoders: (1) Python logging: Add python-json-logger package, (2) Java Log4j/Logback: Use Logstash encoder, (3) .NET: Use Serilog with JSON formatter, (4) Node.js Winston: Enable JSON format option. You can migrate incrementally by configuring JSON output while keeping existing log calls, then gradually refactoring to add structured fields. Many libraries allow mixed format during migration: logger.info("User login", {"user_id": "123"}) works even if old code uses logger.info("User login").