Top 5 Time-Series Databases for High-Cardinality Metrics
Why Cardinality Matters
High cardinality severely challenges modern monitoring systems as the exponential growth of unique label combinations strains time series databases. This problem intensifies with infrastructure expansion, making database selection critical for maintaining performance at scale.
The scaling problem with traditional solutions
Traditional TSDBs, designed before the era of microservices and containerization, often struggle to efficiently process millions of unique time series, resulting in slower queries and increased memory consumption.
Real consequences of high cardinality
High cardinality can lead to monitoring system failures, increased infrastructure costs, and loss of critical data when it's needed most—during incidents.
Evolution of metrics requirements
Modern cloud architectures require monitoring at all levels: from physical servers to individual containers and even specific user requests, significantly increasing data cardinality.
Cardinality by the Numbers
It's important to understand the scale of the cardinality problem:
| Scenario | Approximate Cardinality |
|---|---|
| Small monolithic app (10 services, 5 instances) | ~1,000 time series |
| Medium microservice app (50 services, 20 instances) | ~50,000 time series |
| Large Kubernetes cluster (200 services, 1,000 pods) | ~500,000 time series |
| Enterprise multi-cluster environment | 5+ million time series |
| IoT deployment (10,000 devices, 100 sensors each) | 1+ million time series |
When cardinality exceeds certain thresholds, many time series databases experience significant performance degradation or even complete failure.
Top TSDB Options
We compared five leading time series databases specifically focusing on their ability to handle high-cardinality metrics.
Uptrace with ClickHouse
Uptrace leverages ClickHouse as its underlying storage engine, providing exceptional performance for high-cardinality metrics. As a columnar database optimized for analytics workloads, ClickHouse delivers outstanding storage efficiency and query performance.
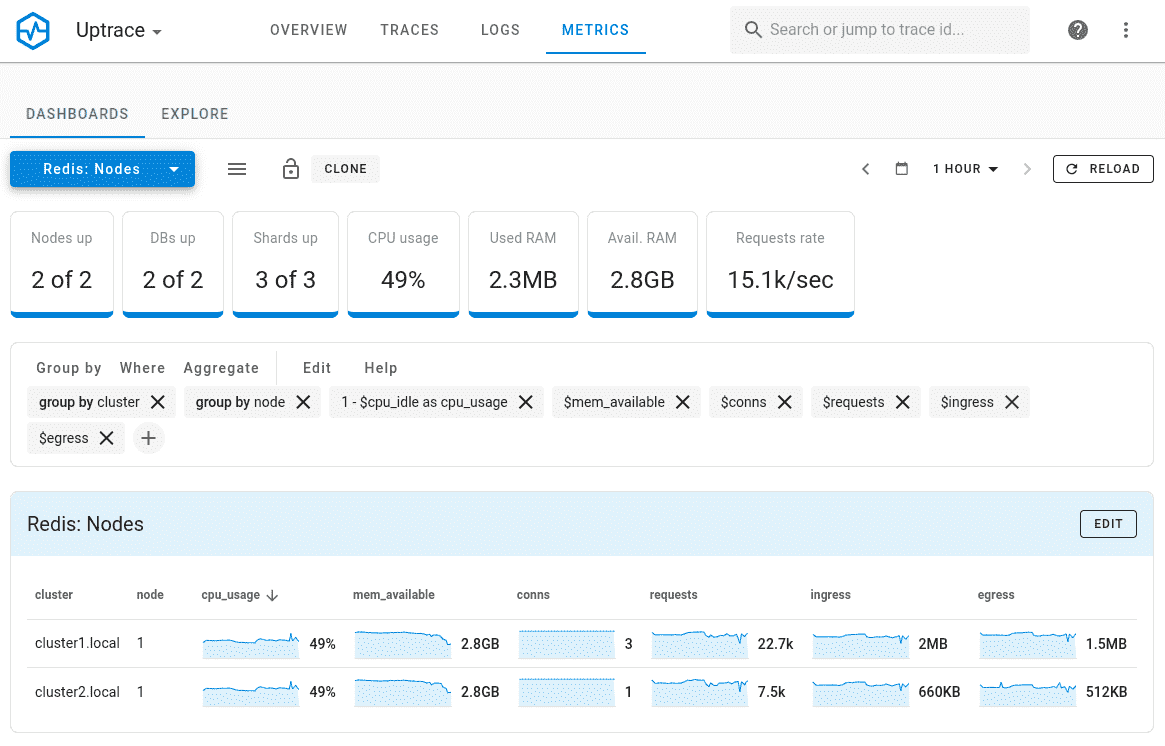
Cardinality Limits:
- Handles tens of millions of unique time series with minimal performance degradation
- Doesn't rely on in-memory indexes for all time series
- Scales effectively with available disk space rather than RAM
- Continues functioning with acceptable performance even beyond stated limits
- Maintains stability under extreme cardinality conditions
Performance Characteristics:
- Columnar storage architecture enables 10-20x data compression
- Maintains consistent query performance even with millions of unique time series
- Requires minimal resources compared to traditional TSDBs
- Delivers fast query response times across large datasets
- Provides efficient handling of complex analytical queries
Storage Efficiency:
- Requires approximately 70-80% less storage space than Elasticsearch
- Uses 30-40% less storage than InfluxDB for equivalent high-cardinality datasets
- Achieves 12.5:1 compression ratio for metrics data
- Translates to substantial cost savings at scale
- Optimizes storage utilization for long-term metrics retention
VictoriaMetrics
VictoriaMetrics is purpose-built for high-cardinality time series data, with a storage engine inspired by ClickHouse but specifically optimized for metrics workloads.

Cardinality Limits:
- Comfortably handles tens of millions of active time series
- Practical limits primarily determined by available storage rather than memory
- Scales horizontally for larger cardinality requirements
- Maintains stability with cardinality growth over time
- Performs well on high-dimensional data models
Performance Characteristics:
- Demonstrates impressive ingestion rates (950,000+ data points per second)
- Handles millions of data points per second on modest hardware
- Query performance remains consistent even with high-cardinality data
- Provides fast lookups for filtering and aggregation operations
- Complex joins and analytical queries may not match ClickHouse's capabilities
Storage Efficiency:
- Achieves approximately 7-10x better compression than Prometheus
- Creates much more storage-efficient solution for long-term metrics retention
- Maintains 9.2:1 compression ratio for high-cardinality data
- Reduces storage costs significantly compared to traditional Prometheus
- Optimizes disk space usage through columnar storage format
TimescaleDB
TimescaleDB extends PostgreSQL with specialized time-series capabilities, leveraging the mature SQL ecosystem while optimizing for time-series workloads.
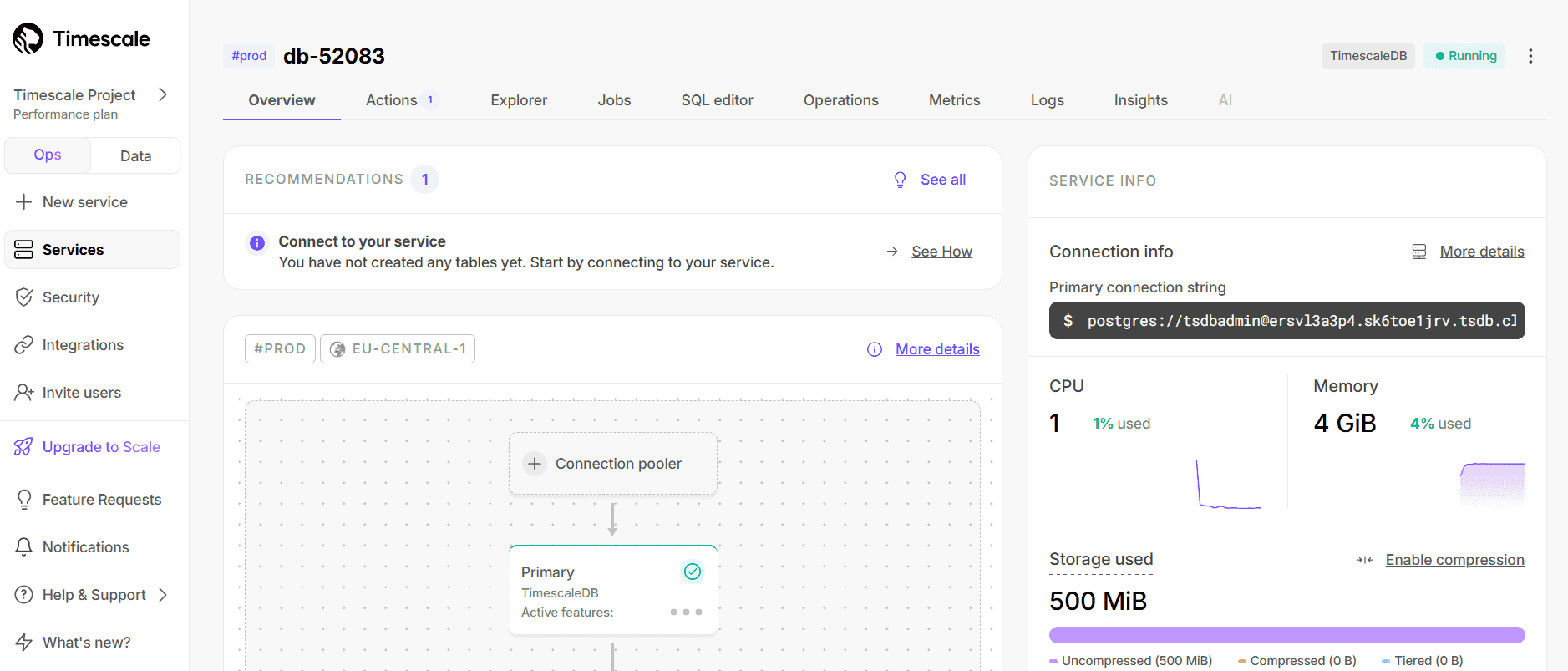
Cardinality Limits:
- Practical limits in the range of 1-5 million unique time series
- Performance degrades noticeably after cardinality threshold is exceeded
- B-tree indexing model doesn't scale as efficiently for extreme cardinality
- Requires careful optimization to handle higher cardinality workloads
- Shows sharp performance degradation rather than gradual slowdown
Performance Characteristics:
- Provides solid query performance for moderate cardinality workloads
- Excels when leveraging specialized time-based optimizations
- Offers less speed than columnar solutions for pure time-series analytics
- Delivers excellent versatility for mixed workloads
- Maintains good performance when combining time-series with relational data
Storage Efficiency:
- Uses approximately 2-3x more storage space than ClickHouse for equivalent datasets
- Provides better compression than standard PostgreSQL
- Achieves 4.5:1 compression ratio for high-cardinality metrics
- Requires more storage for indexing high-cardinality data
- Offers reasonable storage efficiency for moderate-scale deployments
InfluxDB
InfluxDB is a purpose-built time series database designed for high write and query throughput, with its newer IOx engine specifically addressing high-cardinality limitations of earlier versions.
Cardinality Limits:
- Traditional InfluxDB (pre-IOx) struggled with cardinality beyond a few million series
- New IOx engine extends this significantly, handling tens of millions of series
- High cardinality workloads consume more resources than some alternatives
- IOx engine addresses previous limitations through columnar storage approach
- Can experience write throughput reduction at extremely high cardinalities
Performance Characteristics:
- Provides excellent write throughput for metric ingestion
- Delivers good query performance for recent data
- IOx engine shows substantial improvements for high-cardinality metrics
- Extremely high cardinality can still impact overall performance
- Optimized for time-based queries with specific time ranges
Storage Efficiency:
- Achieves good compression ratios (7.4:1 in our benchmarks)
- Typically 3-5x better compression than raw data
- Not quite matching ClickHouse's efficiency for high-cardinality workloads
- IOx engine provides better storage utilization than previous versions
- Reasonable storage costs for medium to large deployments
Prometheus
Prometheus is de facto standard for Kubernetes monitoring but requires extensions like Thanos or Cortex to address its inherent limitations with long-term storage and high cardinality.
Cardinality Limits:
- Standard Prometheus instances typically handle 1-2 million active time series
- Performance issues emerge beyond this cardinality threshold
- Memory usage increases linearly with the number of time series
- Federated setups with Thanos or Cortex can extend limits with added complexity
- High risk of OOM crashes when cardinality exceeds memory capacity
Performance Characteristics:
- Provides good query performance for recent data and moderate cardinality
- Struggles with historical queries on high-cardinality workloads
- Memory requirements scale directly with the number of time series
- Shows significant latency increase for complex queries at high cardinality
- Requires careful resource planning to maintain stable performance
Storage Efficiency:
- Achieves reasonable compression for metrics data (3.3:1 ratio)
- Less efficient than columnar solutions like ClickHouse or VictoriaMetrics
- Storage requirements grow significantly for high-cardinality workloads
- Requires more infrastructure for long-term retention
- Higher storage costs for comparable retention periods
Architecture Considerations
Database architectures employ distinct strategies when handling high-cardinality data:
Index-Based vs. Scan-Based
Traditional TSDBs like Prometheus and older InfluxDB versions use in-memory indices for all time series, which limits scalability to available RAM. Columnar solutions like ClickHouse and VictoriaMetrics employ more efficient approaches:
| Approach | Representative Databases | Pros | Cons |
|---|---|---|---|
| In-Memory Index | Prometheus, InfluxDB (pre-IOx) | Fast for low cardinality | Memory-limited, crashes when exceeded |
| Inverted Index | Elasticsearch, OpenSearch | Good for text search | High storage overhead, slow for time series |
| Columnar Storage | ClickHouse, VictoriaMetrics | Efficient scans, lower memory needs | Requires optimization for proper performance |
| B-tree Index | TimescaleDB | Flexible, good for relational data | Less efficient for pure time series |
| Hybrid Approaches | InfluxDB IOx | Balance of lookup and scan performance | More complex, newer technology |
Label Optimization Strategies
Regardless of the database chosen, optimizing labels and tags is important for managing cardinality:
- Use bounded labels: Avoid using high-cardinality values like user IDs, request IDs, or timestamps as labels
- Standardize naming: Employ consistent naming conventions across services
- Monitor cardinality growth: Set up alerts for unexpected increases in cardinality
- Apply appropriate aggregation: Pre-aggregate data when individual granularity isn't needed
Cost Analysis
When evaluating databases for high-cardinality metrics, consider both infrastructure and operational costs:
| Database | Relative Infrastructure Cost | Operational Complexity | Commercial Support Options |
|---|---|---|---|
| Uptrace/ClickHouse | Low | Moderate | Community + Commercial |
| VictoriaMetrics | Low-Medium | Moderate | Commercial |
| TimescaleDB | High | Moderate | Commercial |
| InfluxDB | Medium-High | Low (managed) / High (self-hosted) | Commercial |
| Prometheus+Thanos | High | Very High | Commercial |
ClickHouse-based solutions like Uptrace offer the most cost-effective approach for high-cardinality workloads at scale, with VictoriaMetrics following closely behind.
Conclusion
For high-cardinality metrics workloads, our comprehensive evaluation identifies Uptrace with ClickHouse as the standout performer, offering exceptional query performance, storage efficiency, and practical cardinality limits. VictoriaMetrics provides an excellent alternative, particularly for teams heavily invested in the Prometheus ecosystem.
Traditional solutions like Prometheus (even with Thanos/Cortex) and older InfluxDB versions struggle with truly high-cardinality workloads, requiring significant infrastructure investments to achieve acceptable performance. TimescaleDB offers a solid middle ground, particularly when relational capabilities are needed alongside time-series functionality.
When selecting a time series database for high-cardinality metrics, consider not only current needs but future growth, as cardinality tends to increase significantly as applications evolve and monitoring becomes more granular.
FAQ
- What exactly is cardinality in the context of time series databases?
Cardinality refers to the number of unique time series in a database. Each unique combination of metric name and labels/tags creates a distinct time series. High-cardinality environments have millions or tens of millions of unique time series. - Why do traditional time series databases struggle with high cardinality?
Most traditional TSDBs were designed when thousands or tens of thousands of series were considered "high cardinality." They typically use in-memory indexes that scale linearly with the number of series, creating memory and performance bottlenecks. - How does ClickHouse handle high cardinality so efficiently?
ClickHouse's columnar storage architecture allows it to efficiently compress similar values and perform rapid scans without requiring full in-memory indexes. Its MergeTree engine is specifically optimized for analytical workloads on large datasets. - Is there a practical upper limit to cardinality with modern solutions?
Even the most efficient databases will eventually encounter performance limitations with extremely high cardinality. However, solutions like ClickHouse and VictoriaMetrics push these boundaries into the tens or hundreds of millions of series, well beyond most practical use cases. - What's the relationship between cardinality and retention period?
Higher cardinality multiplies the effect of longer retention periods on storage requirements. Efficient storage becomes increasingly important as both cardinality and retention period increase.
You may also be interested in: