Kafka Monitoring with OpenTelemetry Collector
Apache Kafka is a widely used distributed streaming platform known for its high throughput, fault tolerance, and scalability. Using the OpenTelemetry Collector kafkametrics receiver, you can collect metrics from Kafka brokers, topics, and consumer groups, then send them to an observability backend for analysis and alerting.
Quick Setup
| Step | Action | Details |
|---|---|---|
| 1 | Install Collector | Deploy OpenTelemetry Collector Contrib on a host with network access to Kafka brokers |
| 2 | Configure kafkametrics receiver | Add kafkametrics receiver with broker addresses and scrapers |
| 3 | Set exporter | Point the OTLP exporter at your backend (e.g., Uptrace) using your DSN |
| 4 | Restart Collector | sudo systemctl restart otelcol-contrib and verify with journalctl |
Why Monitor Kafka?
Monitoring Apache Kafka is critical to ensuring the health, performance, and reliability of your cluster. Kafka observability helps you:
- Detect performance bottlenecks — identify slow consumers and growing partition lag before messages back up.
- Prevent data loss — catch under-replicated partitions and out-of-sync replicas before they affect availability.
- Optimize throughput — understand message rates, broker capacity, and partition distribution to right-size your cluster.
- Troubleshoot issues — correlate Kafka metrics with application traces to pinpoint the root cause of failures.
- Plan capacity — track topic growth and consumer group scaling needs over time.
What is OpenTelemetry Collector?
OpenTelemetry Collector is a vendor-agnostic agent that collects, processes, and exports telemetry data. You deploy it on a host with network access to your Kafka brokers, where it periodically scrapes metrics and forwards them to your chosen backend.
The Collector provides powerful data processing capabilities including aggregation, filtering, transformation, and enrichment. It supports dozens of receivers for different data sources — the kafkametrics receiver is the one purpose-built for Kafka cluster monitoring.
Configuring the Kafkametrics Receiver
To start monitoring Kafka, configure the kafkametrics receiver in /etc/otel-contrib-collector/config.yaml. Replace <FIXME> with your Uptrace DSN:
receivers:
otlp:
protocols:
grpc:
http:
kafkametrics:
brokers:
- localhost:9092
protocol_version: 3.0.0
scrapers:
- brokers
- topics
- consumers
collection_interval: 30s
exporters:
otlp/uptrace:
endpoint: api.uptrace.dev:4317
headers: { 'uptrace-dsn': '<FIXME>' }
processors:
resourcedetection:
detectors: [env, system]
cumulativetodelta:
batch:
timeout: 10s
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/uptrace]
metrics:
receivers: [otlp, kafkametrics]
processors: [cumulativetodelta, batch, resourcedetection]
exporters: [otlp/uptrace]
Kafka 3.7+ (KRaft mode): Starting with Kafka 3.7, ZooKeeper is no longer required — KRaft is the default consensus mechanism. The kafkametrics receiver works with both ZooKeeper-based and KRaft clusters without any configuration change.
Available Scrapers
The kafkametrics receiver supports three scraper types. Configure only the ones you need to reduce collection overhead:
| Scraper | What it collects |
|---|---|
brokers | Broker count in the cluster |
topics | Partition counts, current offsets, oldest offsets, replica counts, in-sync replica counts |
consumers | Consumer group lag, offset, member count |
SASL/SSL Authentication
Production Kafka clusters typically require authentication. The kafkametrics receiver supports SASL and TLS configuration:
receivers:
kafkametrics:
brokers:
- kafka-broker:9093
protocol_version: 3.0.0
scrapers:
- brokers
- topics
- consumers
auth:
sasl:
username: ${env:KAFKA_USERNAME}
password: ${env:KAFKA_PASSWORD}
mechanism: SCRAM-SHA-512
tls:
ca_file: /etc/ssl/certs/ca.pem
cert_file: /etc/ssl/certs/client.pem
key_file: /etc/ssl/certs/client-key.pem
Supported SASL mechanisms include PLAIN, SCRAM-SHA-256, and SCRAM-SHA-512. Use environment variables (${KAFKA_USERNAME}) rather than hardcoding credentials in the config file.
Restart and Verify
After updating the configuration, restart the Collector:
sudo systemctl restart otelcol-contrib
Check the logs for any connection or authentication errors:
sudo journalctl -u otelcol-contrib -f
Look for lines confirming that the kafkametrics receiver started successfully and is scraping your brokers.
Kafka Metrics Reference
The kafkametrics receiver emits the following metrics. Use these names when building dashboards and alert rules.
Broker Metrics
| Metric | Type | Description |
|---|---|---|
kafka.brokers | Gauge | Number of brokers in the cluster |
Topic and Partition Metrics
| Metric | Type | Description |
|---|---|---|
kafka.topic.partitions | Gauge | Number of partitions for a topic |
kafka.partition.current_offset | Gauge | Current offset of a partition |
kafka.partition.oldest_offset | Gauge | Oldest offset of a partition |
kafka.partition.replicas | Gauge | Number of replicas for a partition |
kafka.partition.replicas_in_sync | Gauge | Number of in-sync replicas for a partition |
Consumer Group Metrics
| Metric | Type | Description |
|---|---|---|
kafka.consumer_group.lag | Gauge | Lag of a consumer group for a specific partition (current offset minus consumer offset) |
kafka.consumer_group.lag_sum | Gauge | Sum of lag across all partitions for a consumer group on a topic |
kafka.consumer_group.offset | Gauge | Current offset of a consumer group for a specific partition |
kafka.consumer_group.offset_sum | Gauge | Sum of offsets across all partitions for a consumer group on a topic |
kafka.consumer_group.members | Gauge | Number of members in a consumer group |
All consumer group metrics include group and topic attributes, which let you filter and group by specific consumer groups or topics in your dashboards.
Monitoring Multiple Kafka Clusters
When you run more than one Kafka cluster (e.g., production and staging), use the cluster_alias field to distinguish metrics from each cluster. Define multiple receiver instances with unique names:
receivers:
kafkametrics/prod:
cluster_alias: kafka-prod
brokers:
- prod-broker-1:9092
- prod-broker-2:9092
protocol_version: 3.0.0
scrapers:
- brokers
- topics
- consumers
kafkametrics/staging:
cluster_alias: kafka-staging
brokers:
- staging-broker:9092
protocol_version: 3.0.0
scrapers:
- brokers
- topics
- consumers
service:
pipelines:
metrics:
receivers: [otlp, kafkametrics/prod, kafkametrics/staging]
processors: [cumulativetodelta, batch, resourcedetection]
exporters: [otlp/uptrace]
The cluster_alias value is added as a resource attribute on every metric, so you can filter dashboards and alerts by cluster.
Kafka Distributed Tracing
Metrics tell you what is happening in your Kafka cluster, but distributed tracing shows you how individual messages flow from producers through topics to consumers. By propagating trace context in Kafka message headers, you get end-to-end visibility across your event-driven architecture.
The flow works like this:
- Producer creates a span when publishing a message and injects the trace context (traceparent, tracestate) into the message headers.
- Message sits in the Kafka topic — the time between produce and consume is visible as the gap between the producer and consumer spans.
- Consumer extracts the trace context from the message headers and creates a child span linked to the producer span.
This lets you see the full lifecycle of a message: how long it took to produce, how long it waited in the topic, and how long the consumer took to process it.
Instrumenting Producers and Consumers
Most OpenTelemetry instrumentation libraries provide automatic Kafka tracing. Here are examples for popular languages:
package main
import (
"context"
"log"
"github.com/IBM/sarama"
"go.opentelemetry.io/contrib/instrumentation/github.com/IBM/sarama/otelsarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
config.Version = sarama.V2_0_0_0
brokers := []string{"localhost:9092"}
// Create and wrap the producer with OpenTelemetry instrumentation.
producer, err := sarama.NewSyncProducer(brokers, config)
if err != nil {
log.Fatal(err)
}
defer producer.Close()
producer = otelsarama.WrapSyncProducer(config, producer)
// Create and wrap the consumer with OpenTelemetry instrumentation.
consumer, err := sarama.NewConsumer(brokers, config)
if err != nil {
log.Fatal(err)
}
defer consumer.Close()
consumer = otelsarama.WrapConsumer(consumer)
// Now every Produce and Consume call automatically creates
// spans and propagates trace context through message headers.
msg := &sarama.ProducerMessage{
Topic: "my-topic",
Value: sarama.StringEncoder("hello"),
}
_, _, err = producer.SendMessage(msg)
if err != nil {
log.Fatal(err)
}
}
Alerting on Kafka Metrics
Once metrics are flowing into your backend, set up alerts for the most important failure scenarios.
Consumer Lag Alert
Consumer lag is the most common Kafka alert. A sustained increase means consumers are falling behind, which can lead to message backlogs and processing delays:
- Metric:
kafka.consumer_group.lag_sum - Condition: Value exceeds a threshold for a sustained period (e.g., lag > 10000 for 5 minutes)
- Group by:
group,topic— so you get a separate alert for each consumer group and topic combination
When this alert fires, investigate whether you need more consumer instances, whether the consumer processing logic is slow, or whether there was a burst of messages.
Under-Replicated Partitions Alert
Under-replicated partitions indicate that some replicas are out of sync, which puts data durability at risk:
- Metric:
kafka.partition.replicasminuskafka.partition.replicas_in_sync - Condition: The difference is greater than 0 for more than a few minutes
- Group by:
topic— to identify which topics are affected
Common causes include broker overload, disk I/O bottlenecks, and network issues between brokers.
Broker Count Alert
An unexpected drop in the broker count means a broker has gone offline:
- Metric:
kafka.brokers - Condition: Value is less than your expected broker count
- Severity: Critical — a lost broker means some partitions lose a replica (or a leader)
Troubleshooting Kafka Performance
High Consumer Lag
Symptom: Messages are backing up in topics, and consumers cannot keep up.
Diagnosis: Check the kafka.consumer_group.lag_sum metric, broken down by group and topic.
Common causes:
- Slow consumer processing (e.g., blocking database calls, heavy computation)
- Insufficient consumer instances — Kafka limits parallelism to one consumer per partition
- Network issues between consumers and brokers
- Consumer rebalances triggered by frequent restarts or long processing times
Fixes:
- Add more consumers to the group (up to the number of partitions)
- Optimize consumer processing logic — move heavy work to a thread pool
- Increase
max.poll.recordsandfetch.max.bytesto process larger batches - Increase
max.poll.interval.msif processing takes longer than the default 5 minutes
Under-Replicated Partitions
Symptom: kafka.partition.replicas_in_sync is less than kafka.partition.replicas for one or more partitions.
Meaning: Some partition replicas are lagging behind the leader, which reduces fault tolerance.
Causes:
- Broker overload (CPU, memory, or network saturation)
- Disk I/O bottlenecks on follower brokers
- Network problems between brokers
- A broker is offline or restarting
Fixes:
- Check broker resource usage with system metrics (CPU, disk, network)
- Verify all brokers are healthy with
kafka-broker-api-versions.sh - Reassign partitions to balance load across brokers
- Review
replica.lag.time.max.mssettings
High Request Latency
Symptom: Produce and fetch requests are slow.
Diagnosis: Check broker CPU, disk I/O, and network utilization alongside request latency.
Fixes:
- Increase the number of I/O threads (
num.io.threads) and network threads (num.network.threads) - Optimize batch sizes — larger batches amortize overhead but add latency
- Enable compression (
lz4orzstd) to reduce network transfer - Add more brokers and rebalance partitions to spread the load
OpenTelemetry Backend
Once metrics are collected and exported, you can visualize them using a compatible backend. Uptrace is an OpenTelemetry APM platform that supports distributed tracing, metrics, and logs.
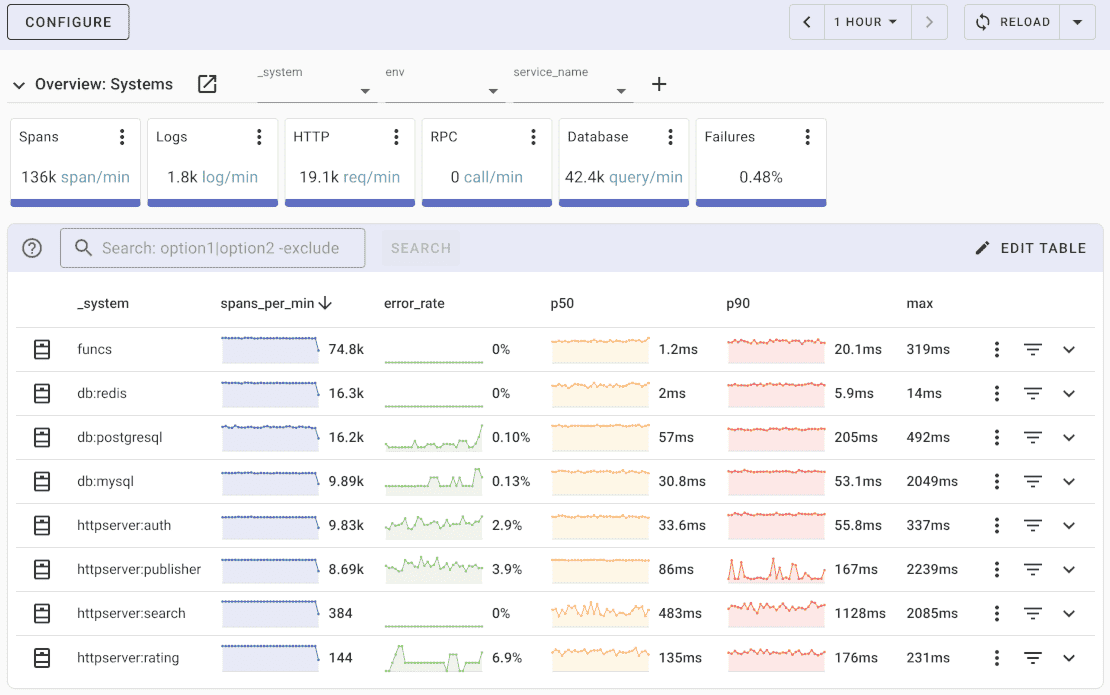
Uptrace provides an intuitive query builder, dashboards, alerting rules with notifications, and integrations for most languages and frameworks. You can try it by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.
What's next?
With Kafka metrics flowing into your observability backend, you can build dashboards to track cluster health and set up alerts on consumer lag and replication issues before they affect your applications.
Related guides:
- OpenTelemetry Collector — learn more about Collector configuration and deployment
- RabbitMQ monitoring — message queue monitoring with OpenTelemetry
- Celery monitoring — Python task queue observability
- Redis monitoring — cache and in-memory store observability
- PostgreSQL monitoring — database metrics collection
- MySQL monitoring — database performance tracking