OpenTelemetry Docker Monitoring with Collector and Docker Stats
Containers start, stop, and move between hosts constantly, so you need a non-intrusive way to track their resource usage. The OpenTelemetry Collector's Docker Stats receiver reads container metrics straight from the Docker daemon API — no agents inside your containers and no application changes.
This guide shows how to collect Docker container metrics with the Collector and export them to Uptrace (or any OTLP-compatible backend).
Prerequisites
Before you begin, make sure you have:
- Docker running with API version 1.25 or higher (
docker version --format '{{.Server.APIVersion}}') - One or more running containers to monitor
- An Uptrace DSN (cloud or self-hosted)
What is OpenTelemetry Collector?
OpenTelemetry Collector is a vendor-agnostic agent that collects telemetry from systems you want to monitor and exports it to an OpenTelemetry backend. It uses a pipeline architecture with receivers, processors, and exporters, letting you collect Docker metrics alongside application traces and logs in a single agent.
The Docker Stats receiver is only available in the contrib distribution, so use the otel/opentelemetry-collector-contrib image.
OpenTelemetry Docker Stats receiver
The Docker Stats receiver connects to the Docker daemon socket and queries container statistics at a fixed interval, exposing CPU, memory, network, and block I/O usage as OpenTelemetry metrics.
Create a config.yaml using your Uptrace DSN:
receivers:
otlp:
protocols:
grpc:
http:
docker_stats:
endpoint: unix:///var/run/docker.sock
collection_interval: 15s
metrics:
container.uptime:
enabled: true
container.restarts:
enabled: true
exporters:
otlp/uptrace:
endpoint: api.uptrace.dev:4317
headers: { 'uptrace-dsn': '<FIXME>' }
processors:
resourcedetection:
detectors: [env, system]
cumulativetodelta:
batch:
timeout: 10s
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/uptrace]
metrics:
receivers: [otlp, docker_stats]
processors: [cumulativetodelta, batch, resourcedetection]
exporters: [otlp/uptrace]
The otlp receiver is optional — keep it if you also want to send application traces and metrics through the same Collector. container.uptime and container.restarts are disabled by default; enable any others you need under metrics.
Run the Collector with Docker Compose
The Collector needs read-only access to the Docker socket to reach the daemon API. Docker Compose is the simplest way to wire that up:
services:
otel-collector:
image: otel/opentelemetry-collector-contrib:0.145.0
container_name: otel-collector
command: ['--config=/etc/otelcol-contrib/config.yaml']
volumes:
- ./config.yaml:/etc/otelcol-contrib/config.yaml
- /var/run/docker.sock:/var/run/docker.sock:ro
ports:
- '4317:4317' # OTLP gRPC
- '4318:4318' # OTLP HTTP
restart: unless-stopped
Start it and follow the logs:
docker compose up -d
docker compose logs -f otel-collector
You should see a line reporting that the docker_stats receiver started. Within one collection interval, container metrics appear in Uptrace.
To run the Collector without Compose, mount the same two volumes with docker run:
docker run -d --name otel-collector --restart unless-stopped \
-v $(pwd)/config.yaml:/etc/otelcol-contrib/config.yaml \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-p 4317:4317 -p 4318:4318 \
otel/opentelemetry-collector-contrib:0.145.0
Docker socket path
The endpoint differs by platform. On Linux and macOS the default is /var/run/docker.sock. On Windows (Docker Desktop), use a named pipe:
docker_stats:
endpoint: npipe:////./pipe/docker_engine
For remote hosts, configure the daemon to listen on TCP and point the receiver at endpoint: http://remote-host:2375 (use TLS in production).
Key Docker metrics
The receiver groups metrics into four categories. The most useful ones for capacity planning and troubleshooting are below; see the receiver docs for the full list.
CPU
| Metric | Description |
|---|---|
container.cpu.utilization | Percent of host CPU used by the container |
container.cpu.usage.total | Total CPU time consumed |
container.cpu.throttling_data.throttled_time | Time the container was throttled |
Memory
| Metric | Description |
|---|---|
container.memory.usage.total | Memory used, excluding cache |
container.memory.usage.limit | Memory limit of the container |
container.memory.percent | Percentage of the limit in use |
Network
| Metric | Description |
|---|---|
container.network.io.usage.rx_bytes | Bytes received |
container.network.io.usage.tx_bytes | Bytes sent |
container.network.io.usage.rx_dropped | Incoming packets dropped |
Block I/O
| Metric | Description |
|---|---|
container.blockio.io_service_bytes_recursive | Bytes read from / written to disk |
container.blockio.io_serviced_recursive | Number of I/O operations issued |
Many metrics — including uptime, restarts, per-CPU usage, and network errors — are disabled by default. Enable them under the receiver's metrics block as shown in the config above.
Troubleshooting
Permission denied on the Docker socket — the Collector process must be able to read /var/run/docker.sock. When running the Collector as a binary or systemd service, add its user to the docker group (sudo usermod -aG docker <user>). The Compose setup above already mounts the socket read-only.
client version is too new / API mismatch — pin the receiver to your daemon's API version:
docker_stats:
endpoint: unix:///var/run/docker.sock
api_version: '1.40' # match `docker version --format '{{.Server.APIVersion}}'`
No metrics in Uptrace — confirm the DSN in config.yaml is correct and the docker_stats receiver is listed under service.pipelines.metrics.receivers. Check the Collector logs (docker compose logs -f otel-collector) for exporter or authentication errors.
Missing block I/O metrics — these depend on your cgroup version. cgroup v2 (default on modern Linux) reports a different set than cgroup v1. Check with mount | grep cgroup.
High Collector CPU usage — raise collection_interval (for example to 30s), disable expensive metrics like container.cpu.usage.percpu, or use excluded_images to skip containers you don't need.
OpenTelemetry Backend
Uptrace is an OpenTelemetry APM that supports distributed tracing, metrics, and logs. You can use it to monitor applications and troubleshoot issues.
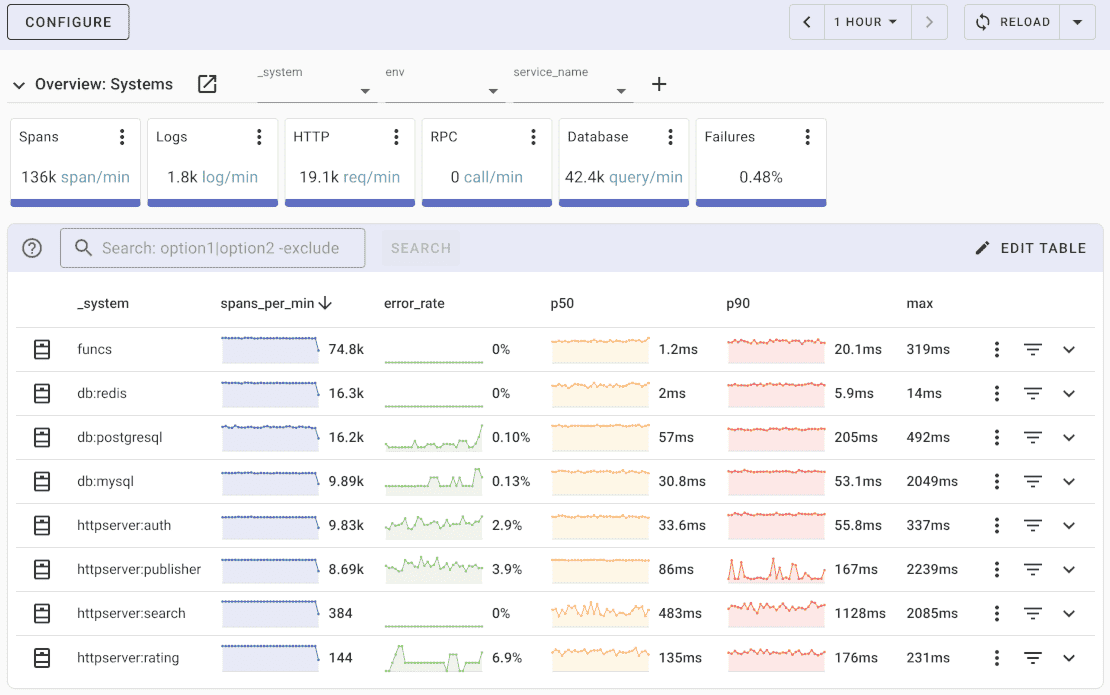
Uptrace comes with an intuitive query builder, rich dashboards, alerting rules with notifications, and integrations for most languages and frameworks.
In just a few minutes, you can try Uptrace by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.
FAQ
Should I use the core or contrib distribution?
The Docker Stats receiver ships only in contrib. Use otel/opentelemetry-collector-contrib.
How is this different from cAdvisor?
The Docker Stats receiver queries the Docker API directly and emits native OTLP metrics. cAdvisor is a standalone daemon better suited to Kubernetes, where it already runs inside the kubelet.
Can I monitor Docker Swarm?
Yes. The receiver talks to the Docker daemon, so deploy one Collector per Swarm node to cover all containers on that node.
How do I exclude test or development containers?
Use excluded_images with exact names or regex patterns, e.g. excluded_images: ['/.*test.*/', '/.*dev.*/'].
How do I add Compose service and project names to metrics?
Map container labels to metric labels:
docker_stats:
container_labels_to_metric_labels:
com.docker.compose.service: service_name
com.docker.compose.project: project_name
What's next?
- Scale up to Kubernetes monitoring for orchestrated deployments
- Collect container logs with the filelog receiver
- Monitor databases with PostgreSQL and MySQL receivers
- Track message brokers with RabbitMQ or Kafka monitoring
- Collect host-level metrics with the host metrics receiver