What's the Difference Between Observability and Monitoring?
What's the Difference Between Observability and Monitoring?
When systems fail, businesses suffer. Downtime means unhappy customers and lost revenue. That's why both monitoring and observability are critical for modern IT operations.
In this article, we'll explore the key differences between monitoring and observability, when to use each approach, and how they work together to keep systems running smoothly.
What is Monitoring?
Monitoring is the process of collecting, analyzing, and using predefined metrics to track a system's health and performance. It focuses on watching known indicators to detect when something goes wrong.
Key Features of Monitoring
- Predefined Metrics: Tracks specific data points like CPU usage, memory, and request times
- Threshold-based Alerts: Notifies when metrics exceed set limits
- Historical Data Analysis: Shows trends over time
- Dashboard Visualization: Provides at-a-glance system status views
Traditional monitoring and modern observability approaches both rely on strong infrastructure monitoring foundations to deliver meaningful insights.
When Monitoring Works Best
Monitoring excels when failure modes are well-understood. For example, database administrators can monitor memory utilization, cache hit ratios, or CPU usage to identify common problems like poorly written queries.
What is Observability?
Observability is the ability to understand a system's internal state by analyzing the data it generates, such as logs, metrics, and traces. It helps determine not just that something is wrong, but why it's happening.
Key Features of Observability
- Comprehensive Data Collection: Gathers metrics, logs, and traces across services
- Dynamic Query Capability: Allows ad-hoc investigation without predefined dashboards
- Correlation Across Systems: Links data from various parts of the infrastructure
- Root Cause Analysis: Enables deeper understanding of why issues occur
The Three Pillars of Observability
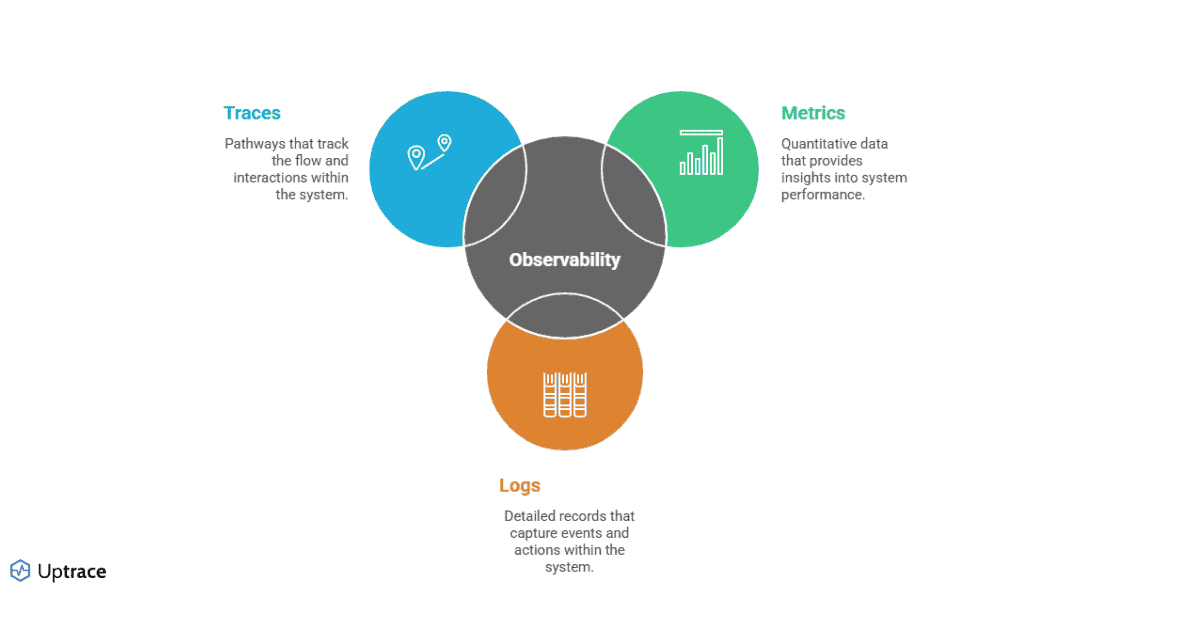
- Logs: Detailed records of events within systems
- Metrics: Measurements captured over time (gauge, delta, cumulative)
- Distributed Tracing: Records of requests flowing through multiple services
Observability vs Monitoring: Key Differences
| Aspect | Monitoring | Observability |
|---|---|---|
| Focus | Known unknowns (predefined metrics) | Unknown unknowns (unexpected issues) |
| Approach | Collects specific metrics | Gathers wide-ranging data |
| Purpose | Detects known issues quickly | Diagnoses complex, unforeseen problems |
| Scalability | Challenging in complex systems | Scales better with increasing complexity |
| Use Case | Stable, predictable environments | Cloud-native, microservices architectures |
| Analogy | Alarm system - alerts when something's wrong | Detective - helps find what's wrong and why |
Do You Need Both Monitoring and Observability?
Yes. Monitoring and observability complement each other:
- Monitoring provides real-time awareness of known issues
- Observability delivers context and deeper insights when problems occur
Modern distributed applications require both approaches. While monitoring helps detect issues quickly, observability helps understand complex failure scenarios in environments where components interact in unpredictable ways.
When Monitoring Is Not Enough
Conventional monitoring works well for simple applications but falls short with modern architectures:
- Microservices create complex dependencies difficult to monitor individually
- Cloud environments introduce variables outside direct control
- Dynamic scaling means constantly changing monitoring targets
- Ephemeral resources appear and disappear regularly
In these scenarios, observability becomes essential because it provides holistic understanding rather than isolated metrics.
Tools for Monitoring and Observability
Monitoring Tools
- Nagios: Traditional monitoring platform with extensive plugin ecosystem
- Zabbix: Open-source monitoring solution for networks and applications
- Prometheus: Time-series database and alerting system popular in cloud-native environments
- Grafana: Visualization platform often paired with Prometheus
- Amazon CloudWatch: AWS native monitoring service
Observability Platforms
- Uptrace: Comprehensive observability solution with integrated distributed tracing
- Datadog: Full-stack observability platform with extensive integration options
- New Relic: Application performance monitoring with observability features
- Honeycomb: Purpose-built observability platform with powerful query capabilities
- Jaeger: Open-source distributed tracing system for microservices
Uptrace, for instance, offers a comprehensive observability solution that integrates distributed tracing, metrics, and logs. It provides powerful querying capabilities and visualization tools, making it easier to correlate data across complex systems.
The most effective implementations integrate multiple tools to provide both monitoring capabilities and observability insights.
Conclusion
Monitoring and observability aren't competing approaches – they're complementary strategies that work best together. Monitoring provides your first alert that something's wrong, while observability helps you understand why it's happening and how to fix it.
As systems become more complex, neither approach alone is sufficient. Organizations need both monitoring for quick detection and observability for deep understanding.
Start by assessing your current capabilities and gradually building both monitoring and observability practices. This balanced approach will help you maintain system reliability, improve performance, and deliver better user experiences.
FAQ
- Is observability just a buzzword for advanced monitoring?
No. While related, observability is fundamentally different in approach. Monitoring measures known metrics, while observability enables understanding of system behavior through outputs, even for unforeseen issues. - Which should I implement first: monitoring or observability?
Start with monitoring for critical services, then gradually add observability capabilities as your understanding and needs grow. - How do cloud environments affect monitoring and observability needs?
Cloud environments increase complexity due to their distributed nature, making observability more crucial. Many cloud providers offer native tools to help implement both approaches. - Can small teams effectively implement observability?
Yes. Start small with key services and focus on the highest-value components. Modern tools make observability more accessible to teams of any size. - How does observability relate to DevOps practices?
Observability supports DevOps by providing insights necessary for continuous improvement, faster troubleshooting, and better collaboration between development and operations. - What role does AI play in modern observability?
AI helps analyze large volumes of observability data, detect anomalies, identify patterns, and even suggest potential root causes that might be missed by human operators.
You may also be interested in: