What is Infrastructure Monitoring? From Basics to Implementation
Infrastructure monitoring delivers critical insights necessary for ensuring peak performance in intricate technology settings. This guide delves into the basics of infrastructure monitoring, its advantages and strategies for effective implementation.
What is Infrastructure Monitoring?
Infrastructure monitoring is the systematic, real-time observation and analysis of IT infrastructure components to ensure optimal performance, availability, and reliability. It provides visibility into the technical foundation that powers business applications and services.
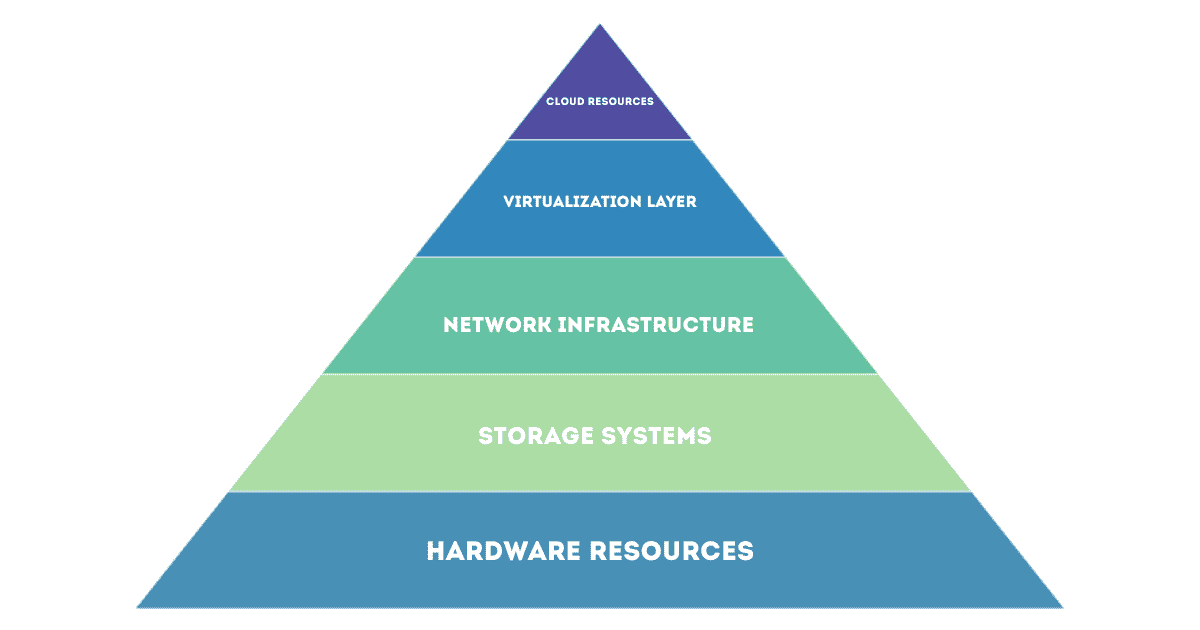
Modern infrastructure monitoring encompasses several critical layers:
- Hardware resources: Physical servers, storage arrays, and networking equipment
- Virtualization layer: Hypervisors, virtual machines, and containers
- Network infrastructure: Switches, routers, firewalls, and load balancers
- Storage systems: Local and networked storage performance and capacity
- Cloud resources: IaaS, PaaS components, and managed services
What distinguishes infrastructure monitoring from other monitoring types is its focus on the underlying technology stack rather than end-user experiences. While application monitoring tracks software performance from a user perspective, infrastructure monitoring examines the foundations these applications depend on.
Infrastructure monitoring collects and analyzes specific performance metrics including:
- CPU utilization rates and processing queues
- Memory allocation, usage patterns, and paging activities
- Storage IOPS, latency, and capacity thresholds
- Network bandwidth consumption, packet loss, and routing efficiency
- System availability, uptime metrics, and response times
Organizations implement infrastructure monitoring to achieve five critical objectives:
- Proactive issue detection: Identifying and resolving problems before they impact services
- Performance optimization: Eliminating bottlenecks and inefficiencies in resource usage
- Strategic capacity planning: Using historical data to forecast future infrastructure needs
- Cost optimization: Identifying resource waste and optimizing infrastructure spending
- Security enhancement: Detecting unusual behavior patterns that may indicate security threats
How Infrastructure Monitoring Works
Infrastructure monitoring operates through a continuous cycle of data collection, analysis, visualization, and alerting. Here's a breakdown of the process:
Data Collection
Monitoring begins with collecting metrics from infrastructure components. This happens through:
- Monitoring agents: Software installed on servers and devices
- API integrations: Direct connections to cloud services and platforms
- SNMP and other protocols: Network-based collection methods
- Agentless monitoring: Remote scanning and probing techniques
Monitoring begins with collecting metrics from infrastructure components. This happens through monitoring agents, API integrations, SNMP, and agentless monitoring techniques.
For network devices, SNMP monitoring is particularly important as it provides a standardized way to collect data regardless of hardware vendor.
These methods gather data points about system performance, resource utilization, and availability status.
Data Processing and Analysis
Once collected, raw infrastructure metrics are processed to:
- Calculate performance averages and baselines
- Identify trends and patterns
- Detect anomalies and deviations
- Correlate metrics across different systems
Advanced infrastructure monitoring tools apply machine learning algorithms to identify potential issues before they become critical problems.
Visualization and Reporting
Processed data is presented through:
- Real-time dashboards showing current infrastructure status
- Historical graphs displaying performance trends
- Heat maps highlighting potential problem areas
- Custom reports for various stakeholders
Effective visualization transforms complex infrastructure metrics into actionable insights.
Alerting and Notification
When metrics exceed defined thresholds, monitoring systems trigger:
- Automated alerts to IT teams
- Escalation processes for critical issues
- Integration with incident management systems
- In some cases, automated remediation actions
Modern infrastructure monitoring solutions use intelligent alerting to reduce noise and focus attention on truly significant issues.
This cycle operates continuously, providing ongoing visibility into infrastructure health and performance.
Key Benefits of Infrastructure Monitoring
Implementing robust infrastructure monitoring delivers significant advantages for organizations:
Preventing Downtime and System Failures
Infrastructure monitoring identifies potential problems before they cause outages by:
- Detecting early warning signs like increased error rates
- Alerting teams to resource depletion issues
- Identifying failing components before complete failure
- Monitoring system dependencies that might affect availability
Studies show that proactive monitoring can reduce unplanned downtime by up to 70%, representing significant cost savings and improved user experience.
Optimizing Performance and Resource Utilization
Continuous infrastructure performance monitoring helps organizations:
- Identify performance bottlenecks in servers and networks
- Optimize resource allocation across systems
- Balance workloads efficiently
- Right-size infrastructure for actual needs
These optimizations lead to better system performance and more efficient resource usage.
Faster Troubleshooting and Problem Resolution
When issues do occur, infrastructure monitoring accelerates resolution by:
- Providing detailed diagnostic information
- Offering historical context for comparison
- Pinpointing the specific components causing problems
- Reducing mean time to resolution (MTTR)
This capability is particularly valuable in complex environments where traditional troubleshooting methods would be time-consuming.
Cost Savings and Efficiency Improvements
Effective monitoring directly impacts the bottom line through:
- Reduced staff time spent on reactive troubleshooting
- Lower resource costs through optimization
- Extended hardware lifespan through better maintenance
- Fewer emergency hardware replacements
- Minimized downtime-related revenue losses
Organizations with mature infrastructure monitoring practices typically see 20-30% reductions in operational costs compared to those with reactive approaches.
Infrastructure Monitoring Use Cases
Infrastructure monitoring serves multiple purposes across different environments:
Server and Hardware Performance Monitoring
The foundation of IT infrastructure monitoring focuses on physical and virtual servers:
- CPU, memory, and disk utilization tracking
- Hardware health monitoring (temperatures, fan speeds, power)
- Server response time measurement
- Operating system performance metrics
- Virtual machine host and guest monitoring
Server infrastructure monitoring ensures the core computing resources remain healthy and responsive.
Cloud Resources Monitoring
For cloud-based infrastructure, monitoring addresses unique challenges:
- Visibility into virtualized resources
- Auto-scaling performance and efficiency
- Service availability across regions
- Cost optimization opportunities
- Cloud provider service limits and quotas
Cloud infrastructure monitoring tools provide specialized features for AWS, Azure, Google Cloud, and other providers.
Network Infrastructure Monitoring
Network components require specific monitoring approaches:
- Bandwidth utilization and throughput
- Latency and packet loss measurement
- Network device health (switches, routers, firewalls)
- WAN and internet connection performance
- Software-defined networking (SDN) monitoring
Network infrastructure monitoring tools help identify connectivity issues that could impact broader system performance.
Data Center Monitoring
For organizations maintaining physical data centers:
- Power usage effectiveness (PUE) tracking
- Temperature and humidity monitoring
- Physical security integration
- Cooling system performance
- Rack space utilization
Data center infrastructure monitoring combines IT and facilities monitoring for comprehensive visibility.
Virtualization Environment Monitoring
Specialized monitoring for virtualized infrastructure includes:
- Hypervisor performance and health
- VM density and resource contention
- Storage I/O performance
- VDI user experience
- Container platform monitoring
This monitoring ensures virtualization platforms provide stable, high-performance services.
Infrastructure Monitoring Best Practices
To maximize the value of infrastructure monitoring, follow these main and proven practices:
Focus on the Most Important Metrics
Not all metrics are equally valuable. Prioritize monitoring:
- High-impact systems that directly affect users
- Resources with limited capacity (e.g., memory, storage)
- Components with historical stability issues
- Critical service dependencies
- Cost-intensive resources
This focused approach prevents information overload while ensuring critical areas receive appropriate attention.
Set Meaningful Alerts and Thresholds
Effective alerting is crucial to monitoring success:
- Define thresholds based on business impact, not technical defaults
- Implement tiered alerting with different severity levels
- Reduce alert noise through correlation and filtering
- Create clear, actionable alert messages
- Regularly review and refine alerting rules
Well-designed alerts ensure teams respond to meaningful issues without suffering from alert fatigue.
Implement Proper Visualization
Data presentation significantly impacts monitoring effectiveness:
- Design dashboards for specific use cases and roles
- Create hierarchical views from overview to detail
- Use color coding consistently to indicate status
- Include contextual information for better understanding
- Make dashboards accessible to relevant stakeholders
Thoughtful visualization transforms monitoring data into actionable intelligence.
Conduct Regular Review and Adjustment
Monitoring is not a set-and-forget activity:
- Review monitoring coverage regularly for gaps
- Adjust thresholds based on observed patterns
- Update monitoring as infrastructure changes
- Retire unnecessary monitoring to reduce overhead
- Incorporate feedback from operations teams
This continuous improvement process ensures monitoring remains relevant and effective.
Integrate with Other Monitoring Systems
Infrastructure monitoring works best as part of a broader observability strategy:
- Connect with application performance monitoring (APM)
- Integrate with log management systems
- Coordinate with security monitoring tools
- Link to configuration management databases
- Feed into IT service management platforms
These integrations provide context that enhances the value of infrastructure metrics.
Tech Recommendation: Application performance directly impacts customer experience. Our APM tools comparison identifies solutions that prioritize real user monitoring.
Choosing the Right Infrastructure Monitoring Tool
Selecting an appropriate monitoring solution requires evaluating several factors:
Essential Features to Look For
The best infrastructure monitoring tools include:
| Feature Category | Key Capabilities |
|---|---|
| Data Collection | Multi-platform support, agentless options, custom metrics |
| Analysis | Anomaly detection, correlation, trend analysis |
| Visualization | Customizable dashboards, flexible graphing, heat maps |
| Alerting | Multi-channel notifications, alert correlation, escalation |
| Integration | APIs, pre-built connectors, extensibility |
| Scalability | High-volume data handling, distributed architecture |
Prioritize features based on your specific environment and requirements.
Tech Recommendation: Effective infrastructure monitoring is critical for system reliability. Explore our comparison of leading monitoring tools to find the best fit for your environment.
Considerations for Different Environments
Your infrastructure type influences tool selection:
- On-premises infrastructure: Tools with broad hardware support and local deployment options
- Cloud environments: Native integration with cloud providers' APIs and services
- Hybrid infrastructure: Unified visibility across both on-premises and cloud resources
- Container platforms: Container-aware monitoring with orchestration integration
- Microservices architectures: Service discovery and dynamic environment support
Choose tools that align with your current architecture while supporting future evolution.
Scalability and Growth Factors
Consider how monitoring needs will change as your infrastructure grows:
- Data retention capabilities for long-term analysis
- Cost model scalability as monitoring expands
- Performance impact on monitored systems
- Administrative overhead as complexity increases
- Licensing model flexibility
The right tool balances current requirements with room for future growth.
Uptrace for Modern Infrastructure Monitoring
Uptrace offers a comprehensive approach to infrastructure monitoring that addresses the challenges of today's complex environments:
- Unified observability: Combines infrastructure, application and distributed tracing in one platform
- Open standards: Built on OpenTelemetry for vendor-neutral data collection
- Intelligent alerting: Reduces noise while ensuring critical issues receive attention
- Intuitive visualization: Makes complex infrastructure relationships understandable
- Cost-effective scalability: Designed for high-volume data without prohibitive costs
Uptrace provides the visibility needed for modern infrastructure without the complexity of traditional monitoring tools.
Try today FOR FREE
Conclusion
Infrastructure monitoring forms the foundation of reliable, high-performance IT operations. By providing visibility into the health and performance of physical and virtual infrastructure components, it enables organizations to prevent outages, optimize resources, and deliver consistent service quality.
Effective infrastructure monitoring requires the right tools, processes, and practices. By focusing on meaningful metrics, implementing appropriate alerting, and choosing solutions like Uptrace that provide comprehensive visibility, organizations can ensure their infrastructure supports rather than hinders business objectives.
As infrastructure continues to evolve toward more distributed, cloud-native architectures, the importance of robust monitoring will only increase. Investing in effective infrastructure monitoring capabilities today creates the foundation for reliable, efficient technology operations in the future.
FAQ
- What's the difference between infrastructure monitoring and APM? Infrastructure monitoring focuses on the underlying hardware, networks, and computing resources that applications run on, tracking metrics like CPU usage, memory, and network performance. Application Performance Monitoring (APM) concentrates on the software layer, measuring response times, error rates, and user experiences within the applications themselves.
- How often should infrastructure monitoring checks run? For critical systems, checks typically run every 30-60 seconds, while less critical components might be monitored at 5-15 minute intervals. The optimal frequency balances early detection of issues against system overhead and data storage costs. Many organizations implement tiered monitoring with different frequencies based on component importance.
- Is agent-based or agentless monitoring better for infrastructure? Both approaches have merits depending on your environment. Agent-based monitoring provides deeper insights and more detailed metrics but requires installation and maintenance on each system. Agentless monitoring offers easier deployment and lower overhead but may provide less detailed information. Many mature infrastructure monitoring strategies utilize both approaches for different components.
- How can I reduce alert fatigue in infrastructure monitoring? To minimize alert fatigue, implement correlation rules to group related alerts, establish meaningful thresholds based on business impact rather than technical defaults, create tiered alert severity levels, schedule regular alert review sessions, and leverage AI-powered tools that can identify truly anomalous behavior patterns.
- What metrics should I prioritize for cloud infrastructure monitoring? Focus on resource utilization (CPU, memory, disk, network), service availability and response times, auto-scaling events and efficiency, regional performance variations, cost optimization opportunities, and integration points between cloud and on-premises systems. Cloud-specific metrics like provisioned vs. actual resource usage are also critical for cost management.
- How much historical data should infrastructure monitoring systems retain? Most organizations keep high-resolution data (seconds or minutes) for 1-2 weeks, hourly aggregates for 1-3 months, and daily summaries for 1-2 years. This tiered approach balances detailed troubleshooting capabilities against storage costs. Regulatory requirements may necessitate longer retention in some industries.
- Can open-source tools provide enterprise-grade infrastructure monitoring? Yes, open-source tools like Prometheus, Grafana, and Zabbix can deliver enterprise-quality monitoring when properly implemented and maintained. These solutions often require more technical expertise to deploy but offer significant cost advantages and customization options compared to commercial alternatives.
- How does infrastructure monitoring integrate with incident management? Modern infrastructure monitoring tools integrate with incident management systems through webhooks, APIs, or direct integrations, automatically creating tickets when issues are detected. More advanced setups include bi-directional communication, allowing incident updates to appear in monitoring dashboards and enabling automated incident creation with relevant diagnostic information attached.
- What's the ROI of implementing comprehensive infrastructure monitoring? Organizations typically see ROI through reduced downtime (often 50-70% less unplanned outages), lower operational costs (20-30% reduction in troubleshooting time), better resource utilization (15-25% improvement), and extended hardware lifespans. These benefits usually offset implementation costs within 6-12 months for mid-sized environments.
- How should infrastructure monitoring evolve for containerized environments? For containerized infrastructure, monitoring must become more dynamic, focusing on ephemeral resources and service-level metrics rather than individual containers. Key adaptations include automated service discovery, container-aware resource tracking, orchestration platform integration, and performance analysis across microservices boundaries.
You may also be interested in: