What is Kafka? Apache Kafka Explained with Use Cases
What is Apache Kafka?
Apache Kafka is a distributed messaging system designed as a commit log with a unique architecture that distinguishes it from traditional message brokers. Created to address LinkedIn's data integration challenges, Kafka implements a partition-based storage model where topics are divided into ordered, immutable sequences of records. Unlike conventional message queues that delete messages after consumption, Kafka retains all published records for a configurable retention period, allowing multiple consumers to read the same messages independently and even replay data streams from specific points.
The system employs a pull-based consumption model, where consumers control their message processing pace while maintaining their position through offsets. This architectural approach enables Kafka to handle massive message volumes with consistent performance, regardless of data size, while providing strong durability guarantees through replication across broker nodes.
Key Features of Apache Kafka
- High Throughput: Capable of processing millions of messages per second
- Scalability: Easily scales horizontally across multiple servers
- Durability: Persists messages on disk and replicates them within the cluster
- Fault Tolerance: Continues operating seamlessly even if individual nodes fail
- Low Latency: Delivers messages with millisecond latency
- Stream Processing: Enables real-time processing of event streams
Kafka's popularity stems from its ability to solve complex data integration challenges across large-scale distributed systems. Organizations increasingly rely on Kafka as a central nervous system for their data, enabling seamless communication between disparate systems and applications.
What is Kafka Used For? Popular Use Cases
Kafka primarily serves as a central data backbone in distributed systems, enabling organizations to build scalable, real-time data pipelines with guaranteed data delivery. Its design specifically addresses the challenges of processing continuous data streams in complex enterprise environments where reliability, throughput, and fault tolerance are critical requirements. Here are the most common use cases for Kafka:
User Activity Tracking
Kafka excels at collecting user activity data from websites and applications in real-time:
- Capturing page views, clicks, and interactions
- Processing user behavior for personalization
- Building real-time analytics dashboards
- Feeding data into machine learning systems for user behavior modeling
Many leading companies like Netflix, LinkedIn, and X use Kafka to track billions of user events daily, enabling personalized recommendations and targeted content.
Real-time Data Processing
Kafka serves as the foundation for real-time data processing applications:
- Stream processing for continuous computation
- Real-time analytics on incoming data streams
- Complex event processing for pattern detection
- Aggregating and transforming data on the fly
Organizations leverage Kafka to process transactions, sensor data, and other time-sensitive information that requires immediate analysis and action.
Service-to-Service Messaging
Kafka provides reliable communication between microservices:
- Decoupling service dependencies
- Enabling asynchronous communication patterns
- Supporting event-driven architectures
- Facilitating service scaling without direct dependencies
In microservice architectures, Kafka acts as a central message bus that allows services to communicate without tight coupling, improving system resilience and scalability.
Operational Metrics Monitoring
Kafka is widely used for collecting and processing operational metrics:
- Gathering performance data from distributed systems
- Centralizing logs and metrics for analysis
- Detecting anomalies in real-time
- Triggering alerts based on metric thresholds
DevOps teams rely on Kafka to monitor complex infrastructures, ensuring systems perform optimally and issues are detected quickly.
Note: For more information about monitoring approaches and best practices, see our guide on Infrastructure Monitoring.
Log Aggregation
Kafka provides an ideal solution for centralizing log data from multiple sources:
- Collecting logs from applications, servers, and network devices
- Providing a unified pipeline for log processing
- Supporting real-time log analysis and alerting
- Enabling long-term storage in systems like Elasticsearch or Hadoop
This centralized approach simplifies troubleshooting and forensic analysis in distributed environments.
Note: For a deeper understanding of how to effectively correlate your logs across distributed systems, see our OpenTelemetry Distributed Tracing Complete Guide.
Apache Kafka Architecture
Understanding Kafka's architecture is essential for leveraging its full potential. Kafka employs a distributed system design that ensures reliability, scalability, and high performance.
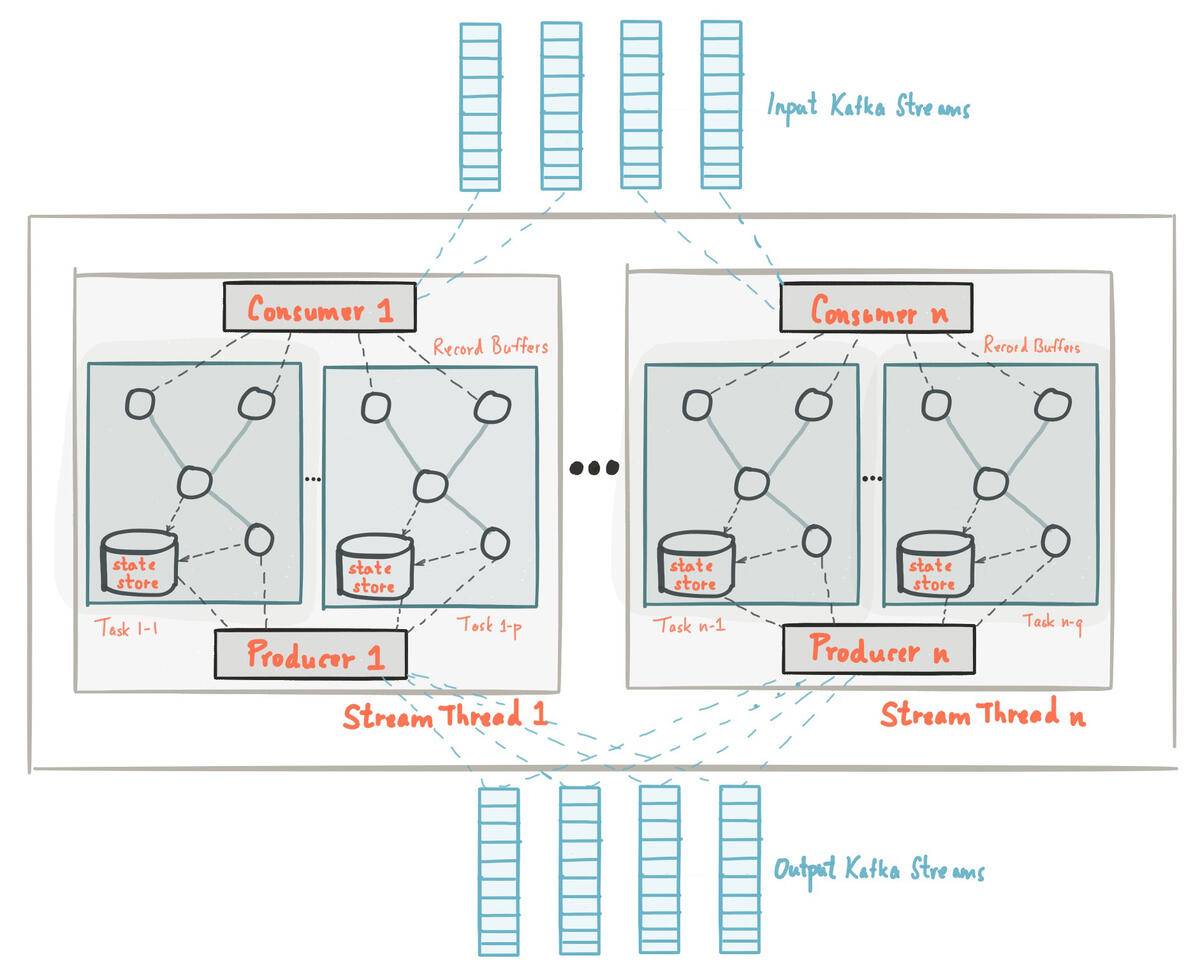
Distributed Cluster Architecture
Kafka's distributed architecture employs a network of broker servers that can span multiple physical locations. Each broker stores a portion of the data, organized into topics—logical data categories that are split into ordered partitions. These partitions are distributed and replicated across the broker network, allowing Kafka to process data streams in parallel while maintaining redundancy.
This distributed nature allows Kafka to:
- Scale horizontally by adding more brokers
- Ensure high availability through replication
- Maintain performance even as data volume grows
How Brokers Work
Brokers are the heart of a Kafka cluster, responsible for:
- Receiving messages from producers
- Storing messages reliably on disk
- Serving messages to consumers
- Managing partitions and replications
Each broker in a Kafka cluster is identified by a unique ID and can handle thousands of partitions and millions of messages per second.
Replication Mechanism and Fault Tolerance
Kafka achieves fault tolerance through replication. Each topic partition is replicated across multiple brokers:
- One broker serves as the leader for a partition
- Other brokers act as followers, replicating the leader's data
- If a leader fails, a follower automatically becomes the new leader
This replication strategy ensures that data remains available even if individual brokers fail, providing crucial reliability for mission-critical applications.
Cluster Scaling
Kafka clusters can scale horizontally by:
- Adding more brokers to increase capacity
- Rebalancing partitions across brokers
- Expanding consumer groups to process more data in parallel
This scalability makes Kafka suitable for both small applications and massive enterprise deployments processing petabytes of data.
Core Concepts of Apache Kafka
To understand how Kafka works, you need to grasp these fundamental concepts that form the backbone of its architecture.
Topics and Partitions
Topics are categories or feed names to which records are published. Topics are split into partitions, which are ordered, immutable sequences of records. Each partition is an ordered log of messages where:
- Each message gets a sequential ID called an offset
- Partitions allow topics to be parallelized across multiple brokers
- More partitions enable greater parallelism but require more file handles
Producers and Consumers
Producers publish messages to topics, determining which partition to send each message to. They can:
- Send messages to specific partitions based on custom logic
- Distribute messages evenly across partitions
- Receive acknowledgments when messages are successfully written
Consumers read messages from topics by subscribing to one or more partitions. They:
- Pull messages from brokers at their own pace
- Track their position in each partition using offsets
- Process messages sequentially within each partition
Brokers
Brokers are the servers that comprise the Kafka cluster. Each broker:
- Manages partitions and handles read and write requests
- Stores partition data according to configured retention settings
- Processes replication of partitions to other brokers
- Handles failure recovery and leader elections
Consumer Groups
Consumer groups enable parallel processing of messages from topics. Within a consumer group:
- Each consumer is assigned specific partitions
- Multiple consumers can process different partitions simultaneously
- Kafka ensures each message is delivered to exactly one consumer within a group
- Adding consumers (up to the number of partitions) increases throughput
These core concepts work together to enable Kafka's distributed, high-throughput messaging capabilities.
Common Challenges When Working with Kafka
While Kafka is powerful, organizations often encounter challenges when implementing and scaling it:
Typical Scaling Difficulties
As Kafka deployments grow, several scaling challenges can emerge:
- Determining optimal partition counts for topics
- Balancing broker resources across the cluster
- Managing consumer lag during high-volume periods
- Dealing with network bandwidth limitations
- Sizing hardware appropriately for expected throughput
Proper planning and monitoring are essential to address these scaling challenges effectively.
How to Avoid Performance Issues
Common performance pitfalls in Kafka deployments include:
- Inefficient partition strategies leading to uneven load
- Poor consumer design causing processing bottlenecks
- Inadequate monitoring leading to late detection of issues
- Suboptimal configuration settings for production workloads
- Insufficient hardware resources for expected volumes
These issues can be mitigated through careful architecture design, thorough testing, and comprehensive monitoring solutions.
How Uptrace Helps with Kafka Monitoring
Effective monitoring is crucial for maintaining healthy Kafka clusters. Uptrace provides comprehensive visibility into Kafka performance and behavior.
Real-time Visualization of Kafka Performance
Uptrace offers detailed dashboards that display:
- Broker throughput and latency metrics
- Topic and partition performance
- Consumer lag and processing rates
- Producer send success and failure rates
- Resource utilization across the cluster
These visualizations help teams quickly understand the health and performance of their Kafka infrastructure.
Tracking Latencies and Message Processing Issues
Uptrace excels at identifying performance bottlenecks:
- End-to-end message latency tracking
- Detection of slow consumers and producers
- Identification of partition imbalances
- Monitoring of request queue times
- Alerting on message delivery SLA violations
This deep visibility allows teams to pinpoint and resolve issues before they impact users.
Quick Identification of Bottlenecks in Kafka Clusters
Uptrace helps diagnose system bottlenecks through:
- Correlation of Kafka metrics with host-level metrics
- Detailed request tracing across producers and consumers
- Visualization of partition leadership distribution
- Monitoring of replication lag across brokers
- Analysis of consumer group behavior and rebalancing events
These capabilities enable proactive identification of potential issues before they become critical.
Integration with Existing Monitoring Systems
Uptrace seamlessly integrates with your existing observability stack:
- Support for OpenTelemetry standards
- Integration with popular logging solutions
- Compatibility with Prometheus and other metrics systems
- API access for custom integrations
- Alerting integration with incident management platforms
For more details on implementing comprehensive Kafka monitoring, check out our guide on OpenTelemetry Kafka Monitoring.
Conclusion
Apache Kafka has established itself as a cornerstone of modern data architectures, providing unparalleled capabilities for handling real-time data streams at scale. Understanding what Kafka is, its architecture, and what it is used for is essential for organizations looking to build resilient, high-performance data pipelines.
When to Choose Kafka
Kafka is the right choice when:
- You need a high-throughput, distributed messaging system
- Your applications require real-time data processing
- You're building event-driven architectures
- You need reliable log aggregation and processing
- Your services need resilient, asynchronous communication
However, Kafka may not be necessary for simpler use cases with low throughput requirements or when a more traditional message queue would suffice.
Additional Resources
To learn more about Apache Kafka and how to effectively use it in your infrastructure:
By implementing Kafka with proper monitoring through tools like Uptrace, organizations can build robust, scalable data systems that deliver reliable performance even under the most demanding conditions.
FAQ
- What is the difference between Kafka and traditional message queues? Unlike traditional message queues, Kafka is designed as a distributed commit log that retains messages for a configurable period, allowing consumers to reprocess data if needed. It also offers higher throughput, better scalability, and more robust partitioning capabilities.
- How many partitions should I create for a Kafka topic? The optimal number of partitions depends on your throughput requirements, consumer parallelism, and broker resources. Start with a number equal to your expected consumer count, and consider factors like retention period and message size when determining the right partition count.
- Is Kafka suitable for small applications? While Kafka excels at large-scale deployments, it may be overkill for very simple applications. However, its reliability and scalability benefits can still be valuable for smaller systems that expect future growth or require strong messaging guarantees.
- How does Kafka ensure no data loss? Kafka ensures data durability through replication across multiple brokers, configurable acknowledgment settings for producers, and persistent storage of messages. By setting appropriate replication factors and acknowledgment levels, you can achieve strong durability guarantees.
- What are the hardware requirements for running Kafka? Kafka benefits from:
- Fast storage (SSDs preferable for high-throughput scenarios)
- Sufficient RAM for page cache utilization
- Multiple CPU cores for handling concurrent requests
- High-bandwidth network interfaces for broker communication
- Can Kafka work across multiple data centers? Yes, Kafka supports multi-datacenter replication through tools like MirrorMaker 2.0. This enables disaster recovery scenarios, data locality for consumers, and geographic distribution of message processing.
- How do I monitor Kafka effectively? Effective Kafka monitoring requires:
- Tracking broker-level metrics (CPU, memory, disk, network)
- Monitoring topic and partition-specific metrics
- Measuring producer and consumer performance
- Watching for consumer lag and replication delays
- Using tools like Uptrace to correlate Kafka metrics with application performance
- What is the relationship between Kafka and Zookeeper? Traditionally, Kafka used Apache Zookeeper for broker coordination, metadata storage, and leader election. However, recent Kafka versions are moving toward removing this dependency through the Kafka Raft (KRaft) protocol, which will eventually eliminate the need for Zookeeper.
You may also be interested in: