Migrating from Datadog to Uptrace
This guide walks you through migrating from Datadog to Uptrace, an OpenTelemetry-native observability platform. You'll learn how to replace Datadog agents with OpenTelemetry Collector, update application instrumentation, and recreate dashboards and alerts.
In short: deploy the OpenTelemetry Collector alongside your existing Datadog agents, replace Datadog SDK calls with OpenTelemetry instrumentation, point the collector at your Uptrace DSN, then run both systems in parallel to validate data parity before decommissioning Datadog.
Why Migrate from Datadog to Uptrace
Organizations migrate from Datadog to Uptrace for several key reasons:
Cost Efficiency:
- Uptrace processes billions of spans on a single server at 10x lower cost
- No per-host pricing or unpredictable custom metrics charges
- Self-hosted option eliminates vendor data egress fees
OpenTelemetry Native:
- Built on open standards - no proprietary agents or lock-in
- Full compatibility with OpenTelemetry SDKs and Collector
- Export data to any backend without re-instrumenting
Unified Observability:
- Traces, metrics, and logs in a single platform
- Automatic correlation between telemetry signals
- Rich dashboards with PromQL-compatible query language
Open Source Flexibility:
- Self-host on your infrastructure or use managed cloud
- Full control over data retention and processing
- Active community and transparent development
What doesn't carry over automatically: Datadog's Continuous Profiler, Watchdog anomaly detection, and Synthetic Monitoring/RUM are proprietary features with no direct OpenTelemetry equivalent. Plan for these separately — see the notes on profiling, synthetics, and RUM in the FAQ below before committing to a migration date.
Migrating from New Relic instead? See the New Relic migration guide — the infrastructure and instrumentation steps are nearly identical, only the vendor-specific SDK calls differ.
Inventory Existing Datadog Resources
First, create an inventory of your current Datadog implementation:
- List monitored hosts and services.
- Document custom metrics and integrations.
- Catalog dashboards, monitors, and alerts.
- Identify critical workflows and visualizations.
You can use the Datadog API to extract this information programmatically:
# Export dashboards list
curl -X GET "https://api.datadoghq.com/api/v1/dashboard" \
-H "DD-API-KEY: ${DD_API_KEY}" \
-H "DD-APPLICATION-KEY: ${DD_APP_KEY}" > dashboards_list.json
# Export monitors
curl -X GET "https://api.datadoghq.com/api/v1/monitor" \
-H "DD-API-KEY: ${DD_API_KEY}" \
-H "DD-APPLICATION-KEY: ${DD_APP_KEY}" > monitors.json
Infrastructure Setup
Setting up the underlying infrastructure is the first step in your migration journey.
Configure Uptrace Environment
Start by setting up Uptrace using either the cloud or self-hosted option:
- Cloud-Hosted Option: Sign up for Uptrace Cloud
- Self-Hosted Option: Install Uptrace on your infrastructure
Once set up, obtain your project DSN from the project settings page. You'll need this DSN to connect your services to Uptrace.
Deploy OpenTelemetry Collector
The OpenTelemetry Collector is the central component that will replace your Datadog agents. It collects telemetry data from various sources and forwards it to Uptrace.
Basic OpenTelemetry Collector configuration:
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
otlp:
endpoint: 'uptrace:4317'
headers:
uptrace-dsn: 'https://<secret>@api.uptrace.dev?grpc=4317'
service:
pipelines:
metrics:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
Install the OpenTelemetry Collector on all hosts currently running the Datadog Agent to ensure comprehensive coverage.
Configure Data Collection Strategies
Depending on your infrastructure, set up appropriate receivers in the OpenTelemetry Collector:
Host Metrics Collection
For system metrics, use the hostmetrics receiver:
receivers:
hostmetrics:
collection_interval: 30s
scrapers:
cpu:
memory:
disk:
filesystem:
network:
load:
paging:
process:
Application Metrics Collection
For applications already exposing Prometheus metrics:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'my-app'
scrape_interval: 15s
static_configs:
- targets: ['my-app:8080']
Legacy StatsD Metrics Collection
For systems using StatsD or DogStatsD:
receivers:
statsd:
endpoint: localhost:8125
aggregation_interval: 60s
Log Collection
For collecting logs from files:
receivers:
filelog:
include: [/var/log/*.log]
start_at: end
operators:
- type: json_parser
Application Instrumentation Changes
Updating your application code to use OpenTelemetry is a critical part of the migration process.
Install OpenTelemetry SDKs
First, choose the appropriate SDK for your application's language:
Migrating Metrics Code
Update your metric collection code to use OpenTelemetry.
Metric Type Mapping:
| Datadog Type | OpenTelemetry Type | Description |
|---|---|---|
| Counter | Counter | Monotonically increasing values |
| Gauge | UpDownCounter | Values that can increase or decrease |
| Histogram | Histogram | Distribution of values |
| Distribution | Histogram | Statistical distribution |
Before (Datadog):
from datadog import statsd
statsd.increment('web.page_views')
statsd.gauge('web.users.online', 123)
statsd.histogram('http.request.duration', 0.25)
After (OpenTelemetry):
from opentelemetry import metrics
meter = metrics.get_meter("my-service")
page_views = meter.create_counter("web.page_views")
users_online = meter.create_up_down_counter("web.users.online")
request_duration = meter.create_histogram("http.request.duration")
page_views.add(1)
users_online.add(123)
request_duration.record(0.25)
Migrating Tracing Code
Replace Datadog tracing with OpenTelemetry distributed tracing.
Before (Datadog):
from ddtrace import tracer
@tracer.wrap()
def process_request(request):
span = tracer.current_span()
span.set_tag("request.id", request.id)
# process request
After (OpenTelemetry):
from opentelemetry import trace
tracer = trace.get_tracer("my-service")
def process_request(request):
with tracer.start_as_current_span("process_request") as span:
span.set_attribute("request.id", request.id)
# process request
For language-specific tracing guides, see:
Implementing Auto-Instrumentation
For many languages, you can use auto-instrumentation to quickly add OpenTelemetry to your applications. Check our guides with instructions for the most popular frameworks.
Updating Logging Code
Implement structured logging with trace correlation. OpenTelemetry automatically injects trace context into your logs, enabling you to correlate logs with traces.
import logging
import json
from opentelemetry import trace
class JsonFormatter(logging.Formatter):
def format(self, record):
log_record = {
"timestamp": self.formatTime(record),
"level": record.levelname,
"message": record.getMessage(),
}
# Add trace context
current_span = trace.get_current_span()
if current_span.is_recording():
context = current_span.get_span_context()
log_record["trace_id"] = format(context.trace_id, "032x")
log_record["span_id"] = format(context.span_id, "016x")
return json.dumps(log_record)
logger = logging.getLogger("app")
handler = logging.StreamHandler()
handler.setFormatter(JsonFormatter())
logger.addHandler(handler)
For more on logging with Uptrace, see monitoring logs.
Visualization and Alerting
Transferring your dashboards and alerts from Datadog to Uptrace ensures continuity in your monitoring capabilities.
Converting Dashboards
When recreating dashboards in Uptrace:
- Start with critical dashboards first identified in your inventory
- Use Uptrace's prebuilt dashboards where applicable
- Convert Datadog queries to Uptrace's PromQL-compatible syntax
- Validate visualizations match your expectations
Migrating Alerts
To transfer your alerts:
- Extract alert definitions from Datadog
- Create equivalent alerts in Uptrace
- Test alert triggering to ensure proper functionality
- Update notification channels to match your current setup
DQL to PromQL Translation Guide
When migrating from Datadog to Uptrace, you'll need to translate Datadog Query Language (DQL) to Prometheus Query Language (PromQL). Here are common translation patterns:
Basic Metrics Queries
| Datadog Query (DQL) | Uptrace Query (PromQL) | Description |
|---|---|---|
avg:system.cpu.user{host:web-*} | avg(system_cpu_user{host=~"web-.*"}) | Simple average with regex matching |
sum:http.requests{service:api} | sum(http_requests_total{service="api"}) | Summing metrics with tag matching |
avg:system.load.1{*} by {host} | avg(system_load1) by (host) | Grouping by a tag |
Time Aggregation
| Datadog Query (DQL) | Uptrace Query (PromQL) | Description |
|---|---|---|
avg:system.cpu.user{*}.rollup(avg, 60) | avg_over_time(system_cpu_user[1m]) | 1-minute average |
sum:http.requests{*}.rollup(sum, 300) | sum_over_time(http_requests[5m]) | 5-minute sum |
Rate and Change Calculations
| Datadog Query (DQL) | Uptrace Query (PromQL) | Description |
|---|---|---|
per_second(sum:http.requests{*}) | rate(http_requests_total[5m]) | Request rate (per second) |
diff(avg:system.mem.used{*}) | deriv(system_memory_used_bytes[5m]) | Rate of change |
Naming Conventions
When migrating metrics, follow these naming conversion rules:
- Replace dots with underscores:
- Datadog:
system.cpu.user - Uptrace:
system_cpu_user
- Datadog:
- Add appropriate unit suffixes:
- Datadog:
http.request.duration - Uptrace:
http_request_duration_seconds
- Datadog:
Validation and Testing
Before decommissioning Datadog, run both systems in parallel to validate data consistency.
Data Consistency Checks
Verify that metrics in Uptrace match those in Datadog:
- Compare metric values for identical time periods
- Check alert triggering in both systems
- Ensure trace completeness across services
- Validate log collection and correlation
Parallel Running Period
Run Datadog and Uptrace simultaneously for 1-2 weeks:
- Compare dashboards side-by-side
- Verify alerts fire correctly in both systems
- Check that all services are reporting to Uptrace
- Validate data retention and query performance
Once you confirm data parity, gradually migrate teams to Uptrace before disabling Datadog agents.
OpenTelemetry Backend
Uptrace is an open source APM for OpenTelemetry that supports distributed tracing, metrics, and logs. You can use it to monitor applications and troubleshoot issues.
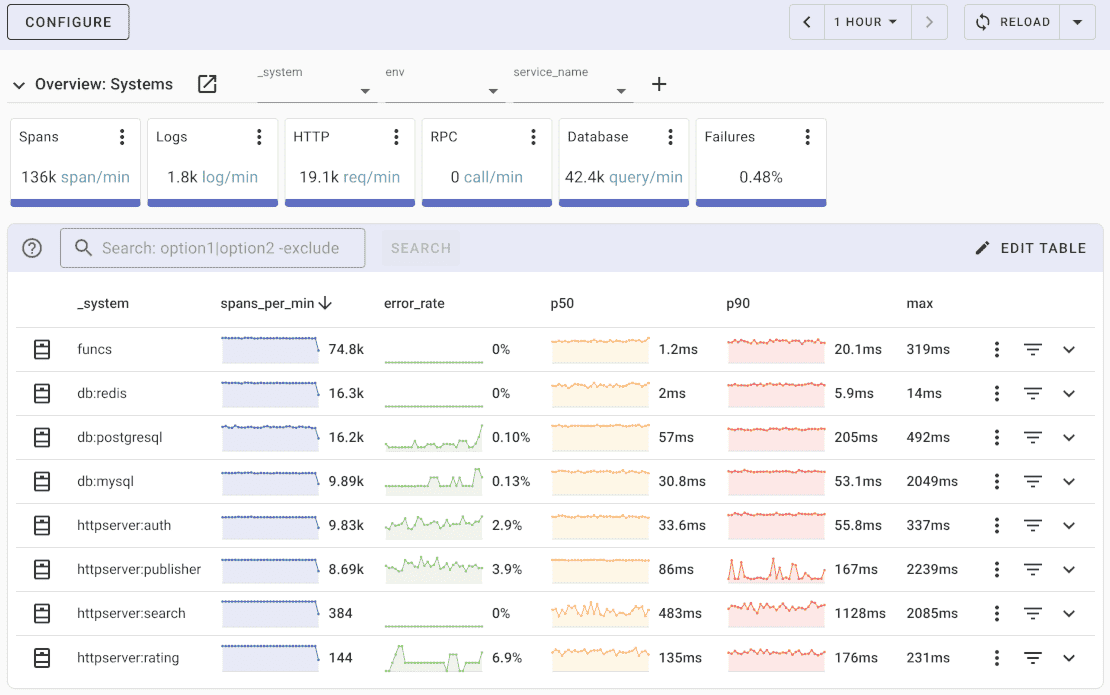
Uptrace comes with an intuitive query builder, rich dashboards, alerting rules with notifications, and integrations for most languages and frameworks.
Uptrace can process billions of spans and metrics on a single server and allows you to monitor your applications at 10x lower cost.
In just a few minutes, you can try Uptrace by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.
FAQ
How long does a typical Datadog migration take?
Migration timeline depends on the complexity of your setup. Simple deployments can migrate in a few days, while complex multi-service architectures may take several weeks for full validation.
Can I run Datadog and Uptrace simultaneously during migration?
Yes, this is the recommended approach. Run both systems in parallel to validate data parity before fully transitioning to Uptrace.
Do I need to change my application code?
Yes, you'll need to replace Datadog SDK calls with OpenTelemetry SDKs. However, many frameworks support auto-instrumentation, reducing code changes significantly.
What about Datadog integrations for third-party services?
Most Datadog integrations have OpenTelemetry equivalents. The OpenTelemetry Collector provides receivers for common services like databases, message queues, and cloud providers.
Can I keep using StatsD metrics?
Yes, OpenTelemetry Collector includes a StatsD receiver that accepts DogStatsD-formatted metrics, allowing gradual migration of custom metrics.
How do I handle Datadog APM traces during migration?
OpenTelemetry traces are semantically similar to Datadog traces. The main changes are attribute naming conventions and SDK initialization code.
What if I have Datadog Synthetic tests?
Uptrace has its own synthetic monitoring for uptime and endpoint checks. For browser-based or multi-step synthetic tests, you'll still need a dedicated tool like Checkly or Grafana Synthetic Monitoring alongside Uptrace.
How do I handle exception and error tracking?
Replace ddtrace's automatic error capture with OpenTelemetry's exception recording (span.record_exception() / RecordException()). See exception tracking for setup details and how Uptrace groups and surfaces errors.
What's Next?
Your Datadog migration journey continues with these resources:
- Data Ingestion: Explore all ingestion methods including OpenTelemetry SDK, Collector, and Prometheus
- Log Collection: Set up log pipelines with Vector or FluentBit
- Kubernetes: Deploy collectors in Kubernetes environments
- Exception Tracking: Set up error and exception tracking to replace Datadog Error Tracking
- Synthetic Monitoring: Set up uptime and endpoint checks to replace basic Datadog Synthetics
- Instrumentation Guides: Find framework-specific tutorials in our guides section
- OpenTelemetry: Learn more about OpenTelemetry fundamentals
- Also migrating from New Relic? See the New Relic migration guide